AI Engineering Notes: Foundation Models and AI Engineering (Ch.1)
March 1, 2025
These are my personal summaries and observations from reading AI Engineering by Chip Huyen. They are not a comprehensive review — just the notes and takeaways that stood out to me. I highly recommend picking up the book for the full picture.
This chapter covers the foundations of building AI applications with foundation models — key concepts around language models, tokenization, and the emerging discipline of AI engineering.
Foundation Models and Language Models
Language models have come a long way. They started out with simple probabilistic approaches using unigram and n-gram models. For example, computing probabilities like:
P("apple" | "like")P("apple" | "I like")
Over time, these models became much more sophisticated with the use of deep learning.
Tokenization
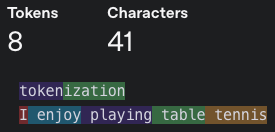
For any language model, there needs to be a step to break up text into tokens — this process is called tokenization. Here is how GPT-4 tokenizes text:
- For the GPT-4o tokenizer, one token generally corresponds to ~4 characters of text
A vocabulary contains the words that a given model can recognize. Different models have very different vocabulary sizes:
- GPT-4 vocab size: 100,526
- Mistral 8x7B: 32,000
In general, there is an <oov> (out-of-vocabulary) token that represents unrecognizable tokens. You can think of it as a dummy value.
Why tokenize with tokens instead of words or characters?
- Benefit over characters: Tokens retain the semantic representation of the word, whereas individual characters do not.
- Benefit over words:
- More efficient for the model to learn since there are fewer tokens than words.
- Able to process unknown words such as “chatgpt-ing” — this is important to account for future new words as language continues to evolve over time.
Types of Language Model
- Masked Language Model (BERT and its variants): Good at understanding the overall context of the text, thus performant on non-generative tasks like Sentiment Analysis.
- Autoregressive Language Model (GPT and most of the latest LLMs): “Generating one word at a time.” This is the mainstream approach right now and generally follows a decoder-only architecture.
How to Train Your Model
Most language models are now trained in a self-supervised way using next token prediction. The labels are inferred from the training data itself.
Imagine you have Harry Potter as the training text. Given the tokens for “Harry”, the model will be trained to predict “Potter”:
Input: <BOS> Harry
Output: Potter
How much data do you need for pretraining? The tl;dr is: a lot. Researchers propose a Chinchilla scaling law, suggesting approximately 20 tokens per parameter.
What is a Foundation Model?
The author proposes that to be considered a foundation model, the model needs to satisfy two criteria:
- Can be used in various AI applications for different needs
- Has good general capabilities
Multimodal models with image understanding are foundation models. The CLIP model is an embedding model that is part of the component of Vision-LLMs (VLLM).
How to work with foundation models:
- Prompt engineering — crafting effective instructions
- Retrieval-Augmented Generation (RAG) — use a database to supplement the instructions
- Finetuning — adapt the model to your specific use case
AI Engineering
What makes AI engineering different from ML engineering / MLOps?
As pretraining foundation models is expensive, few companies have the capabilities to do it. But the foundation models are increasingly accessible via APIs. One can simply make a single API call to get model predictions instead of hosting their own models. This fundamentally changes the workflow.
Use Cases
The author tabulates the use cases in Github open-sourced projects (n=205):
| Use Case | Percentage |
|---|---|
| Coding | 30.4% |
| Chatbots | 26.5% |
| Information Aggregation | 12.7% |
| Image / Video Production | 12.7% |
| Workflow Automation | 11.3% |
| Writing | 3.4% |
| Education | 1.5% |
| Data Organization | 1.5% |
Another observation is that companies are faster to deploy internal-facing applications (internal knowledge management) than external-facing ones.
Detailed breakdown of key use cases:
- Coding: Useful for code documentation, refactoring, migrating frameworks
- Writing: Composing sales, marketing, team communication materials and SEO content
- Chatbot: Customer support (SQ Assistant!), coach, companion, therapist, voice assistants
- Information Aggregation: Summarization (Cash Support ML Customer Case Summarization)
- Workflow Automation: Automate repetitive tasks, data entry, synthesize data
Planning AI Applications
The author proposes evaluating the necessity of building an AI application with decreasing urgency:
- If you don’t build, competitors can build the AI and make you obsolete (e.g. Website builder?)
- If you don’t build, you miss opportunities to boost profits and productivity (e.g. Better chatbot to improve user experience)
- Haven’t figured how to incorporate AI into business — Can have a R&D department for prototyping
Once the use case is established, the team can consider whether to build in-house or buy an industry solution.
Types of AI Integration into Applications
There are several dimensions to consider:
- AI-centric vs. complementary
- Reactive vs. proactive
- Dynamic vs. static
How to create a deep moat for your AI products?
- Technology, data, distribution channel
- A startup can get to market first and gather sufficient usage data to continually improve their products — data will be the moat
- In other words, startups can figure out the product-market fit faster through iteration
ML Development Cycle
- Setting expectations and defining success metrics
- Milestone planning
- Multiple industry blogs share the sentiment that 0 to 60 is easy, but 60 to 100 (production grade) becomes extremely difficult
- Maintenance — swapping models for better performance
AI Engineering Tech Stack
- Application Development — requires rigorous evaluation and good interface
- Model Development — dataset engineering, model training, finetuning, inference optimization
- Infrastructure — model serving, managing data and compute GPU resources, monitoring
How is AI Engineering Evolving?
The author proposes a shift in workflow paradigm:
- ML Engineering: Data → Model → Product
- AI Engineering: Product → Data → Model
Key trends:
- Less focus on model training but more emphasis on building applications through model adaptation (prompt engineering, RAG, finetuning)
- More pressure on efficient training and inference optimization
- More emphasis on end-to-end evaluation