AI Engineering Notes: Evaluation Methodology (Ch.3)
March 2, 2025
These are my personal summaries and observations from reading AI Engineering by Chip Huyen. They are not a comprehensive review — just the notes and takeaways that stood out to me. I highly recommend picking up the book for the full picture.
This chapter dives deep into the evaluation of AI systems. Evaluation is arguably the most critical and yet most under-invested area in production AI — and this chapter does a great job laying out the landscape.
Introduction
Many echoes that the biggest hurdle to bringing AI applications to production is evaluation. I see many of “experts” writing about this on LinkedIn.

Evaluation comes hand in hand with logging, tracing, and monitoring in the said system. Without these components, engineers and product owners can’t understand the quality of the AI system and make improvements. Traditional NLP models relied on reference-based evaluation to compute a score such as ROUGE, BLEU.
Challenges of Evaluating Foundation Models
- No ground truths available for open-ended tasks
- From a simple direct / rule-based comparison, it has become a sophisticated task that involves fact-checking, reasoning, and completeness
- Black box models make it more difficult to debug with a mechanistic approach (Anthropic uses a mechanistic approach to improve interpretability)
- Lack of funding to invest in evaluation compared to having the latest fanciest LLM — inadequate investment leads to poor quality guardrails
Standard Language Modeling Metrics
Entropy-Based Metrics
Perplexity on a dataset — you need to have the logits of the prediction to calculate the metrics (generally only available with open-weight models).
Key observations about perplexity:
- More structured data gives lower expected perplexity
- The bigger the vocabulary, the higher the perplexity
- The longer the context length, the lower the perplexity (more information in the context)
- For close-sourced models, the companies have stopped reporting the perplexity of models
- Post-training (RLHF, Finetuning) changes the vocab distribution, hence also has an effect on the perplexity of the model
Exact Evaluation
- Assertion — e.g. does this output a valid JSON format?
- Similarity measurements against reference data (Reference-based evaluation):
- Exact Match — checking word by word against a ground truth
- Lexical similarity — how many similar words / n-grams they overlap: BLEU, ROUGE, METEOR++, TER, CIDEr
- Pros: Good at telling you how much the model has memorized a certain template or format
- Cons: The prediction can score low if it has similar semantic meaning but uses different wording. High lexical similarity scores don’t always mean better responses. For example, code gen benchmarks using BLEU can score high by memorizing the order of the reference code
- Semantic similarity — compare embeddings of the ground truths with the prediction, e.g. BERTScore, MoverScore
- Multi-modal — can use CLIP encoder to compute joint embeddings
LLM-as-a-Judge
Benefits of the LLM Judge
- Low-cost, can output reasonings
- Some research has shown that GPT-4 and humans (85%) are more aligned than the human labels (81%) agreement
- Less labor-intensive than coordinating a group of human annotators
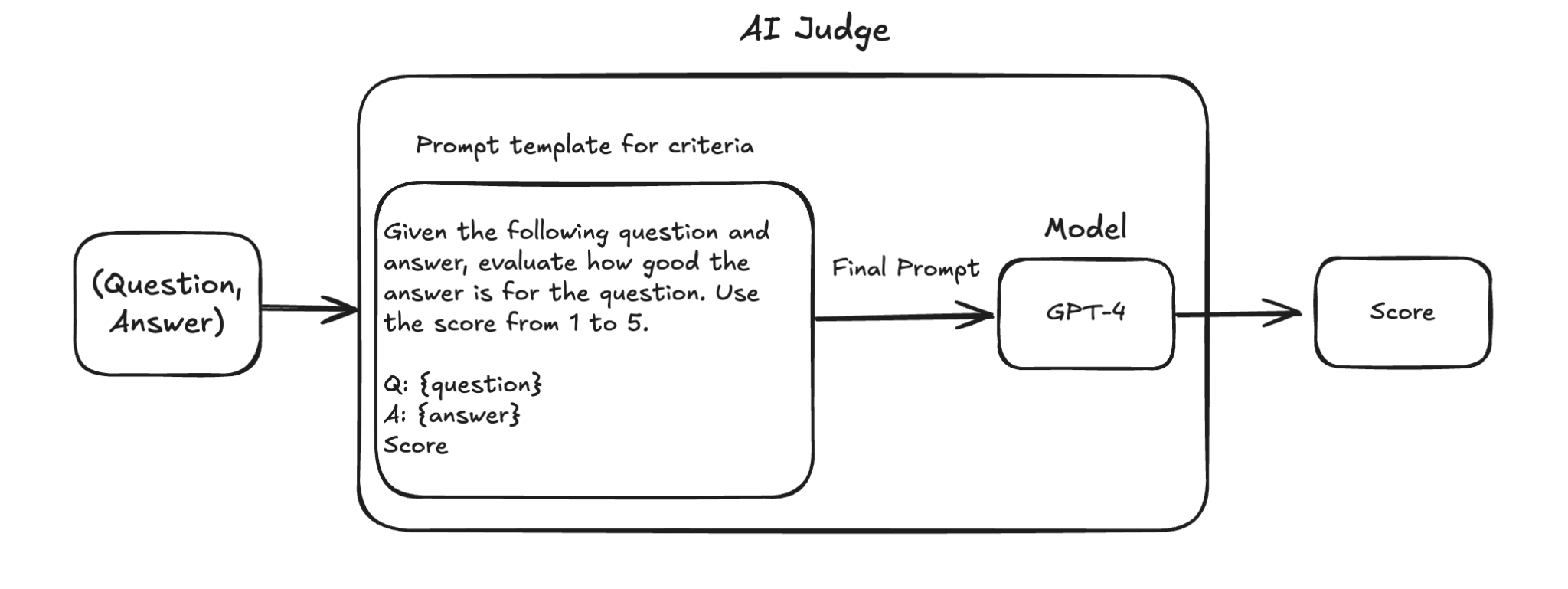
How Does a LLM Judge Work?
A prompt template defines criteria, takes (question, answer), sends to a model (e.g. GPT-4), and outputs a score.
Limitations of the LLM Judge
- Inconsistency — results may vary across runs
- Criteria Ambiguity — always check the model / prompt for the judge
- Biases of LLM judge:
- Positional bias — LLM prefers the answer that comes first
- Verbosity bias — longer response gets more points
- Self-bias — Claude model as judge would prefer Claude-generated prediction
How to Choose Models as a Judge?
- Cost and latency — does it have to be a big model?
- Open question: can a judge be weaker than the model being judged?
- One research direction is to look at small, specialized judges such as JudgeLM, Prometheus. But internal research has shown mixed results.
- Reward Model: Cappy with 360m parameters (2023) produces a score between 0 and 1
- Reference-based judge: BLEURT (2020), Prometheus (prompt, generated response, reference response, rubric)
- Preference Model: pairwise evaluation — PandaLM, JudgeLM
Comparative Evaluation (Elo Rating)
A prominent example is the LMSys Chatbot Arena, where users can compare outputs of different models using the same prompt. It works surprisingly well in practice and allows ties.
Not all questions should be answered by preference.
Metrics used for pitting model A against model B is called “win rate”. If in 10 matches, model A is preferred 6 times, win rate = 60%.
Challenges of Comparative Evaluation
- Scalability bottlenecks — data intensive, may not cover various use cases comprehensively
- One potential solution: better matching algorithms so that with fewer comparisons, the ranking would still be stable
- Lack of standardization and quality control — Anyone can join LMSys Chatbot Arena, no common consensus or guidelines on the prompt
- Difficult to quantify the comparative win rate % to actual boost in performance (e.g. win rate 60% doesn’t mean 60% better at the task)
The Direction Forward
The direction is probably a mix of human-in-the-loop, LLM judge, and rule-based evaluation.
Some tips from production:
- Engage product owners early on to understand their needs and pain points
- Custom judge for use cases seems to be the most valuable
- Make it easy for projects to plug and play
- Always have a calibration dataset ready to explain the quality of the LLM judge