Building a Training Dataset for Diffusion Distillation: Lessons from LADD
March 31, 2026
Target audience: ML engineers building training data pipelines for text-to-image models, or anyone curious about the data decisions behind distillation.
Table of Contents
- Overview
- What LADD Needs from Data
- Collecting Prompts from 9 Sources
- Classification: Why Keywords Fail
- Filling Coverage Gaps
- Balancing the Length Distribution
- The Final Pipeline
- Lessons Learned
Overview
LADD (Latent Adversarial Diffusion Distillation) compresses a 50-step diffusion model into a 4-step student. The student never sees real images — it trains entirely on text prompts, using the teacher to generate synthetic latents and a discriminator to provide adversarial feedback.
This means the dataset is just a list of prompts. But “just prompts” hides real complexity: the prompts must be diverse enough that the student generalizes across content types, detailed enough to stress prompt adherence, and balanced across a taxonomy of subjects, styles, and cameras.
This post traces the decisions, mistakes, and fixes involved in building a 12K-prompt dataset for LADD distillation of the Z-Image model — from initial benchmark collection through classification, gap-filling, and length balancing.

1. What LADD Needs from Data
Unlike standard fine-tuning (which needs image-text pairs), LADD’s adversarial training loop uses prompts as conditioning only. The teacher generates latents from each prompt, the student tries to shortcut the teacher’s trajectory, and the discriminator judges realism.
Three properties make or break the dataset:
- Subject and style diversity. If the dataset is 80% portraits, the student will underperform on landscapes, food, architecture, and abstract art. The training signal must cover the full output space.
- Prompt length and detail. Distilled models lose prompt adherence first — they merge objects, drop attributes, ignore spatial relationships. Long, detailed prompts (30-40 words) stress-test this weakness. A dataset of 8-word prompts like “a red car” trains a student that can’t handle “a red vintage convertible parked on a cobblestone street at golden hour with dramatic rim lighting.”
- Language coverage. Z-Image uses a Qwen3 text encoder that handles both English and Chinese natively. The dataset should include Chinese prompts to preserve this capability.
2. Collecting Prompts from 9 Sources
We aggregated prompts from 8 established text-to-image evaluation benchmarks and one curated external dataset, evaluating each for diversity, quality, and length characteristics.
| Source | Count | Avg Words | Why it’s useful |
|---|---|---|---|
| MJHQ-30K | 30,000 | 29.5 | Curated Midjourney prompts across 10 categories |
| CVTG-2K | 2,000 | 33.9 | Text rendering prompts (signs, labels, UI) |
| OneIG-ZH | 1,320 | — | Chinese-language prompts across 6 dimensions |
| PartiPrompts | 1,257 | 11.1 | Compositional evaluation (“a cat on top of a dog”) |
| GenAI-Bench | 1,188 | 23.4 | Mixed complexity, spatial relationships |
| DPG-Bench | 1,065 | 67.1 | Dense, paragraph-length descriptions |
| GenEval | 553 | 7.6 | Object co-occurrence and counting |
| LongText-Bench | 320 | 135.4 | Very long text rendering prompts |
| DrawBench | 108 | 13.0 | Google’s evaluation suite |
We rejected SDXL-1M (Falah) — 1 million template-generated prompts that were people-only, photorealistic-only, and would have drowned out every other source.
Download quirks
Four benchmarks needed custom downloaders:
- GenEval isn’t a HuggingFace dataset — we download the JSONL directly from GitHub
- OneIG-ZH requires the config name
"OneIG-Bench-ZH", not"zh" - CVTG-2K is a zip file containing nested JSON with a
data_listarray structure - LongText-Bench has Chinese prompts but no language field — we added CJK Unicode detection to auto-tag them
3. Classification: Why Keywords Fail
Every prompt needs to be classified into a MECE taxonomy (14 Subjects x 7 Styles x 8 Cameras) so we can measure and enforce coverage. The first attempt used keyword matching. It failed badly.

The keyword problem
Consider: “A woman wearing a red dress in a garden.”
Keyword matching hits “dress” first and classifies this as Fashion (S9). But the primary subject is a person — it should be People (S1). This cascaded across the dataset:
- Objects (S10) ballooned to 2,544 prompts because every prompt mentioning any object got caught
- Chinese Cultural (S13) had only 6 prompts because keyword lists don’t cover Chinese concepts well
- 80% of prompts defaulted to Photorealistic (T1) because implicit styles (“dreamy ethereal quality”) don’t match keyword lists
Claude-based reclassification
We split the 7,811 benchmark prompts into 4 chunks and used parallel Claude subagents to reclassify each with semantic understanding. The rules:
- People take priority when humans are present, even alongside animals, clothing, or settings
- Implicit styles are detected: “dreamy ethereal quality” maps to Mixed/Experimental (T7)
- Chinese cultural content is identified by subject matter, not just language
The result: a properly balanced taxonomy with Chinese Cultural going from 6 to 112 prompts, and Text/Typography correctly expanding from 370 to 1,649 as CVTG-2K prompts were properly categorized.
4. Filling Coverage Gaps
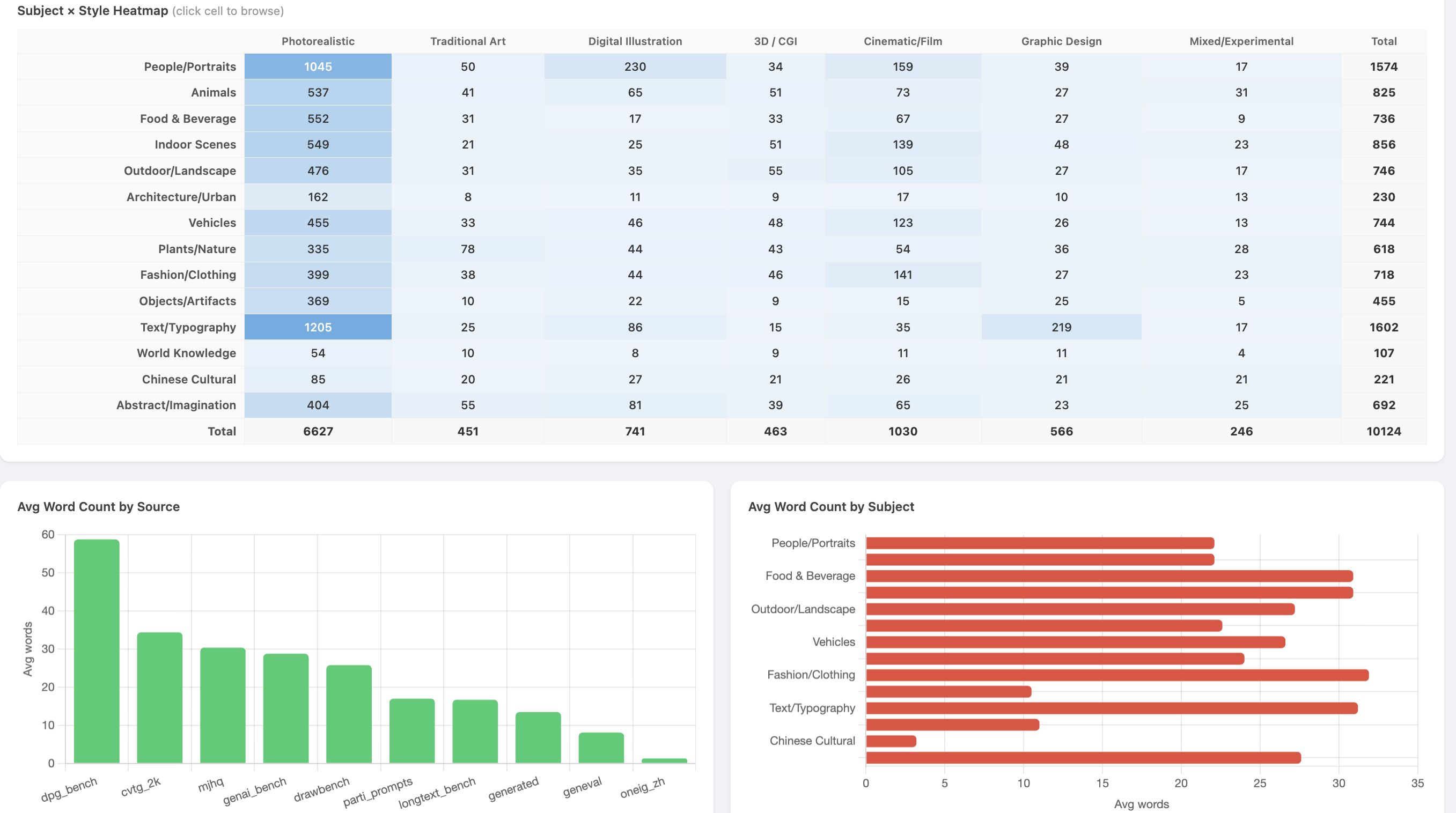
After reclassification, 80 of 98 Subject x Style cells were below 50 prompts. Seventeen cells had zero — all concentrated in 3D/CGI (T4), Cinematic/Film (T5), and Mixed/Experimental (T7) styles.
Generating 3,347 gap-fill prompts
Four parallel Claude subagents generated prompts to fill every cell to a minimum of 50. Each agent handled a group of subjects with exact per-cell quotas, style keyword requirements, and camera angle distributions.
The length problem
The generated prompts averaged only 14 words. Without explicit length targets, LLMs default to concise outputs: “3D render of a crystal goblet on marble” when we need “3D render of an ornate crystal goblet with diamond-cut facets sitting on a polished white marble table, warm amber spotlight casting long shadows, dark moody background with subtle fog, octane render, 8K detail.”
Four more subagents expanded each prompt to 30-40 words by adding concrete visual details — colors, materials, textures, lighting, atmosphere, composition — while preserving the original subject and style classification.
5. Balancing the Length Distribution
With benchmark prompts (many short) and gap-fill prompts (now 30-40 words) combined, the word count distribution was bimodal: a spike at 10-20 words and a long tail past 50.

Why not random rejection?
The naive approach — Gaussian acceptance sampling, where each prompt has a probability of being kept based on its word count — destroys sparse cells. A Subject x Style cell with exactly 50 prompts (all short) loses 40 of them to the length filter, breaking coverage.
Stratified resampling
The solution preserves coverage while reshaping the distribution:
- Hard cutoffs: drop English prompts with fewer than 10 or more than 80 words. Chinese prompts are unaffected (they use characters, not whitespace-delimited words).
- Per-cell stratified keep: for each Subject x Style cell, guarantee a minimum of 30 prompts. In cells with surplus, preferentially keep longer prompts by sorting by word count and retaining the top half.
- MJHQ mid-range fill: add 5,000 MJHQ prompts in the 25-50 word range to build the center of the bell curve.
Why not keep everything?
With all 30K MJHQ prompts included, the dataset balloons to 40K — but MJHQ dominates at 73%. The student would effectively train on Midjourney-style prompts with benchmark prompts as noise. Controlled sampling maintains source diversity.
6. The Final Pipeline
The dataset is built with a single configurable command:
python data/build_dataset.py --sample mjhq=15000 --balance-lengths
This produces approximately 12,000 prompts with:
- Mean ~35 words, median ~32
- All 98 Subject x Style cells with at least 30 prompts
- Balanced source representation (no single source exceeds 40%)
- 85% English, 15% Chinese
The pipeline is fully configurable:
| Flag | Default | Purpose |
|---|---|---|
--sample SOURCE=N |
all | Limit prompts per source |
--min-words |
10 | Drop short English prompts |
--max-words |
80 | Drop long English prompts |
--balance-lengths |
off | Stratified resampling + MJHQ fill |
--min-per-cell |
30 | Minimum per Subject x Style cell |
--subjects |
all | Filter to specific subjects |
--dry-run |
off | Preview without saving |
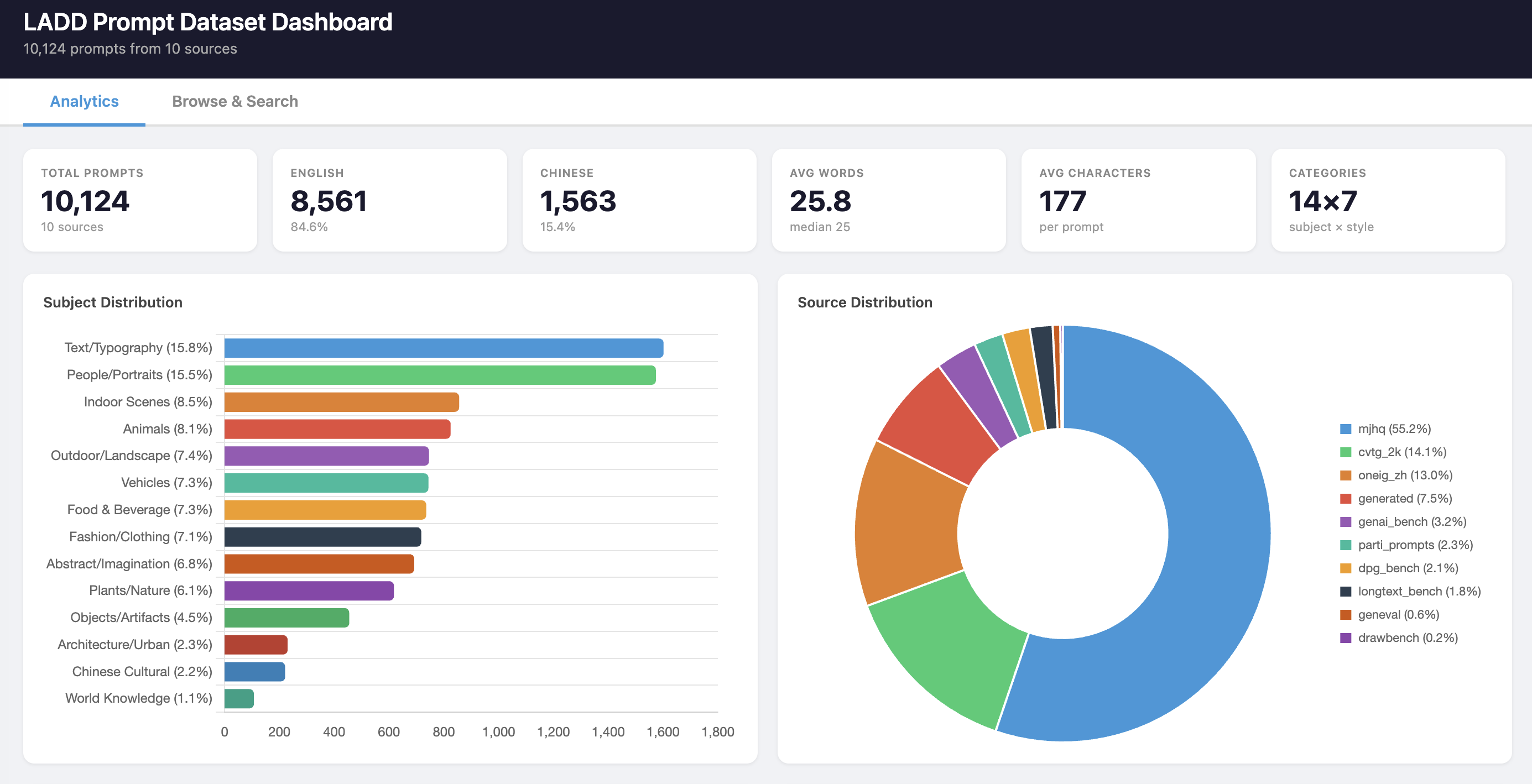
A local dashboard provides interactive analytics and a filterable prompt browser. Here’s what the final dataset looks like:
KPIs, subject distribution, and source breakdown:
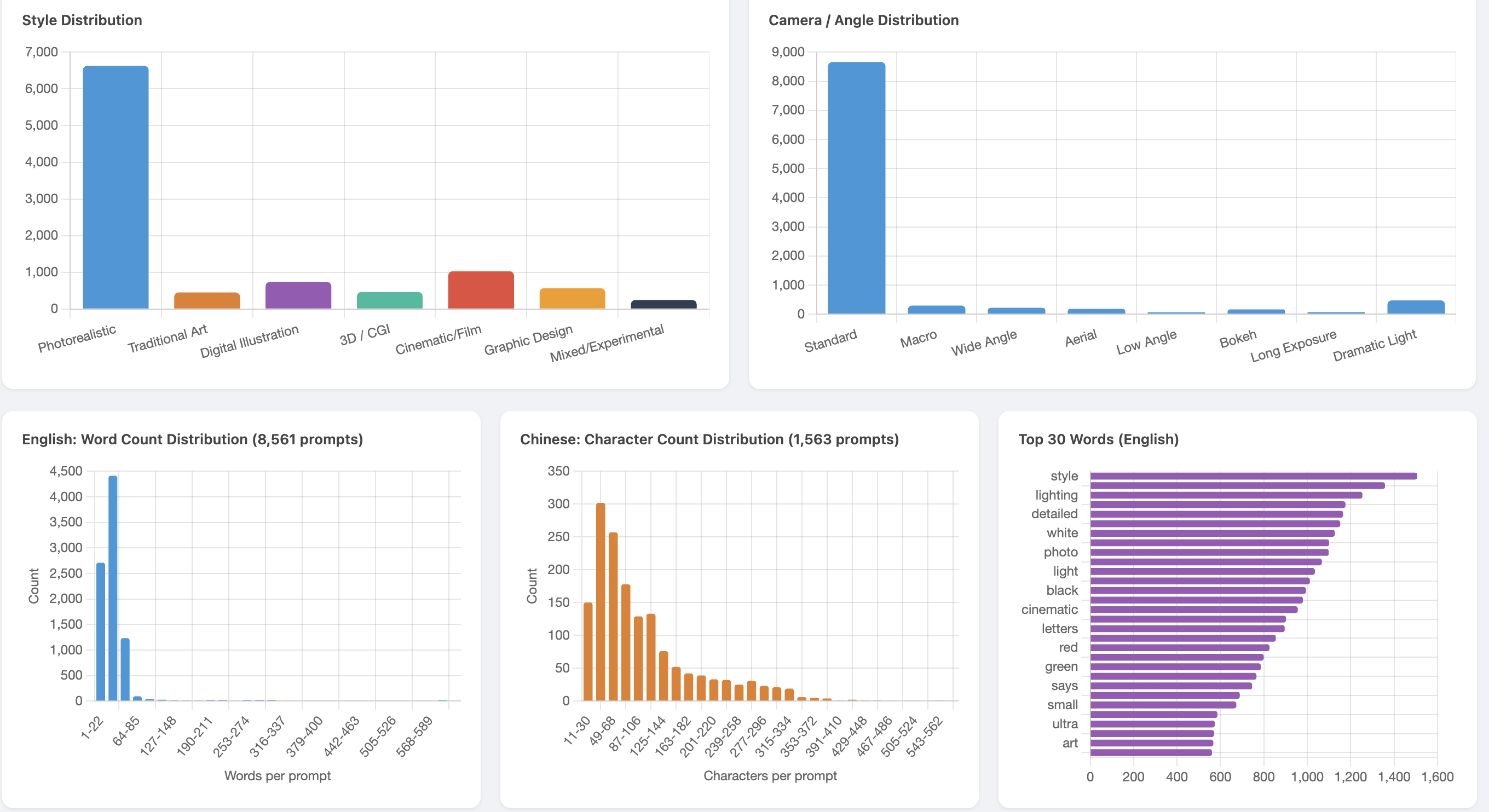
Style and camera distributions with word count histograms:
Subject x Style coverage heatmap and average word count by source:
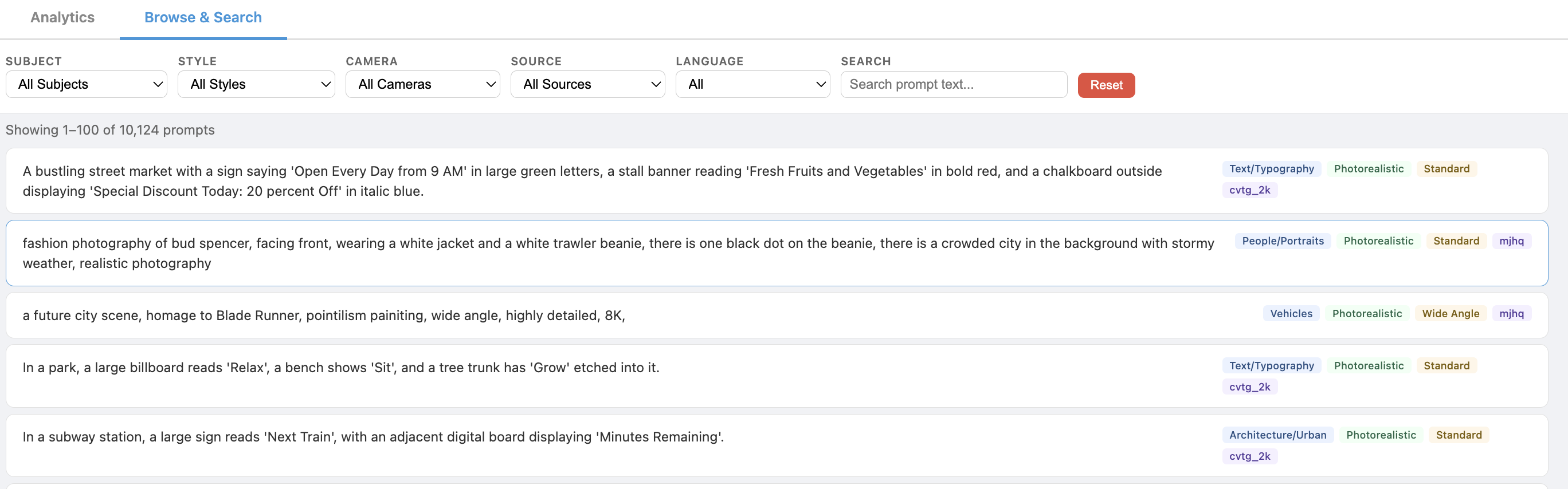
Browsing English prompts with human-readable category tags:
Browsing Chinese prompts:
7. Lessons Learned
Keyword classification is unreliable. For ambiguous prompts, keyword matching misidentifies the primary subject 20-30% of the time. Semantic classification via LLM is worth the cost for datasets under 50K — it takes minutes with parallel agents and produces dramatically better taxonomy coverage.
Generated prompts need explicit length targets. When asked to “generate a prompt about X,” LLMs default to 10-15 word outputs. Specifying “generate a 30-40 word prompt with specific visual details including lighting, materials, textures, and atmosphere” gets the right result.
Length balancing must be coverage-aware. Random rejection sampling (Gaussian acceptance, uniform filtering) destroys sparse taxonomy cells. The fix is stratified: guarantee minimums per cell first, then reshape the distribution with the surplus.
Source diversity matters more than volume. 10K well-balanced prompts from 9 sources produces better training outcomes than 30K dominated by one source. Each source has different prompt characteristics — DPG-Bench’s dense paragraphs, GenEval’s short compositional tests, OneIG-ZH’s Chinese cultural references — and the student needs exposure to all of them.
Chinese prompts need separate handling. Word-count filters using whitespace splitting don’t apply to Chinese text. CJK character detection is needed for language tagging, and character-count thresholds replace word-count thresholds for filtering.