Building a Training Dataset for Diffusion Distillation: Lessons from LADD
March 31, 2026
Target audience: ML engineers building training data pipelines for text-to-image models, or anyone curious about the data decisions behind distillation.
Table of Contents
- Overview
- What LADD Needs from Data
- Harvesting Prompts at Scale
- Deduplication: 970K to 630K
- Classification: From Keywords to Hybrid
- Enforcing Balance
- The Final Dataset — Dashboard, t-SNE, Browse
- Lessons Learned
- Appendix: Download Reality vs. Documentation
Overview
LADD (Latent Adversarial Diffusion Distillation) compresses a 50-step diffusion model into a 4-step student. The student never sees real images — it trains entirely on text prompts, using the teacher to generate synthetic latents and a discriminator to provide adversarial feedback.
This means the dataset is just a list of prompts. But “just prompts” hides real complexity: the prompts must be diverse enough that the student generalizes across content types, detailed enough to stress prompt adherence, and balanced across a taxonomy of subjects, styles, and cameras.
We started with a 12K seed dataset built from T2I evaluation benchmarks — gap-filled and length-balanced with Claude-generated prompts. That was enough to validate the pipeline, but not enough to train on: at batch size 256, the model exhausts 12K prompts in ~47 iterations and spends the rest of training recycling stale gradients. This post covers how we scaled that to 527K diverse, deduplicated, and classified prompts by harvesting from 9 large-scale sources, running two-stage deduplication, building a hybrid classification system that works on verbose VLM captions, and applying a 15% subject cap to enforce balance.

1. What LADD Needs from Data
Unlike standard fine-tuning (which needs image-text pairs), LADD’s adversarial training loop uses prompts as conditioning only. The teacher generates latents from each prompt, the student tries to shortcut the teacher’s trajectory, and the discriminator judges realism.
Three properties make or break the dataset:
- Subject and style diversity. If the dataset is 80% portraits, the student will underperform on landscapes, food, architecture, and abstract art. The training signal must cover the full output space.
- Prompt length and detail. Distilled models lose prompt adherence first — they merge objects, drop attributes, ignore spatial relationships. Long, detailed prompts (30-40 words) stress-test this weakness. A dataset of 8-word prompts like “a red car” trains a student that can’t handle “a red vintage convertible parked on a cobblestone street at golden hour with dramatic rim lighting.”
- Language coverage. Z-Image uses a Qwen3 text encoder that handles both English and Chinese natively. The dataset should include Chinese prompts to preserve this capability.
How many prompts?
Neither the ADD nor LADD papers disclose exact dataset sizes, but we can back into estimates:
| Paper | Iterations | Batch Size | Total Presentations |
|---|---|---|---|
| ADD (Sauer et al., 2023) | 4,000 | 128 | 512K |
| LADD conservative estimate | 10,000 | 256 | 2.5M |
| LADD likely estimate | 10,000 | 512 | 5M |
LADD samples prompts from SD3’s full training set (millions of unique prompts), so repeats are rare. At 12K prompts with 10K iterations and batch size 256, each prompt would be seen ~213 times. At 527K, that drops to ~5 times — comparable to the original paper’s regime.
2. Harvesting Prompts at Scale
The dataset blends small high-quality benchmarks with large-scale caption datasets. The benchmarks (used in the original 12K seed) provide curated evaluation-style prompts. The large-scale sources provide volume, diversity, and the verbose captions that push prompt adherence.
Seed benchmarks (12K)
We started with 8 T2I evaluation benchmarks plus one curated Midjourney dataset:
| Source | Count | Avg Words | Why it’s useful |
|---|---|---|---|
| MJHQ-30K | 30,000 | 29.5 | Curated Midjourney prompts across 10 categories |
| CVTG-2K | 2,000 | 33.9 | Text rendering prompts (signs, labels, UI) |
| OneIG-ZH | 1,320 | — | Chinese-language prompts across 6 dimensions |
| PartiPrompts | 1,257 | 11.1 | Compositional evaluation (“a cat on top of a dog”) |
| GenAI-Bench | 1,188 | 23.4 | Mixed complexity, spatial relationships |
| DPG-Bench | 1,065 | 67.1 | Dense, paragraph-length descriptions |
| GenEval | 553 | 7.6 | Object co-occurrence and counting |
| LongText-Bench | 320 | 135.4 | Very long text rendering prompts |
| DrawBench | 108 | 13.0 | Google’s evaluation suite |
We rejected SDXL-1M (Falah) — 1 million template-generated prompts that were people-only, photorealistic-only, and would have drowned out every other source.
Large-scale sources (970K)
To reach training scale, we harvested from 8 additional large-scale sources plus the existing seed pool — a mix of real user prompts, VLM-generated captions, and curated collections:
| Source | Prompts | Type | License | Notes |
|---|---|---|---|---|
| DiffusionDB | 300,000 | Real Stable Diffusion user prompts | CC0 | Massive internal duplication. NSFW filtered. |
| Recap-DataComp-1B | 250,000 | LLaVA-1.5 recaptions of web images | CC-BY-4.0 | Schema mismatches across parquet shards. |
| DenseFusion-1M | 200,000 | Multi-VLM fused captions | Apache-2.0 | Very long/detailed (~80-150 words). |
| ShareGPT4V-PT | 100,000 | GPT-4V synthetic captions | Apache-2.0 | Extracted from multi-turn conversation format. |
| JourneyDB | 50,000 | Midjourney user prompts | CC-BY-NC-SA | Gated access. Stripped MJ params (--ar, --v). |
| SAM-LLaVA-10M | 30,000 | LLaVA captions of SAM images | Research | Field is txt, not caption. |
| Wukong | 15,000 | Chinese web captions | Apache-2.0 | Original HF org (noah-wukong) was 404. |
| DOCCI | 13,936 | Human-written dense captions | CC-BY-4.0 | Highest quality. Dataset script broken; used raw JSONL. |
| Existing seed pool | 11,158 | Benchmarks + gap-fill | Mixed | Already classified from prior pipeline. |
AnyText-3M was planned but had been removed from HuggingFace.
Quality filters applied per-prompt: minimum 8 English words or 15 Chinese characters, maximum 200 words, fewer than 2 URLs, no boilerplate strings (“stock photo”, “getty images”), at least 70% alphabetic characters. Cross-source exact dedup removed only 64 prompts — almost no verbatim overlap between sources. But exact matching only catches identical strings; the real redundancy is semantic.
3. Deduplication: 970K to 630K
970K raw prompts contain massive redundancy — especially DiffusionDB, where users submit the same prompt with different generation parameters. We ran two-stage dedup: surface-level (exact and near-exact matches) followed by semantic (same concept, different wording).

Stage 1: MinHash LSH (surface dedup)
MinHash with Locality-Sensitive Hashing catches near-identical text efficiently. Each prompt is shingled (split into overlapping character n-grams), hashed into a 128-permutation MinHash signature, and grouped by LSH bands. Pairs with Jaccard similarity above 0.7 are flagged as duplicates; the higher-quality version is kept (scored by word count sweet spot, source quality prior, and visual keyword density).
Worked example. Consider two DiffusionDB prompts that differ only in generation parameters:
A: “a majestic wolf standing on a cliff at sunset, digital art, highly detailed” B: “a majestic wolf standing on a cliff at sunset, digital art, highly detailed, 4k”
Step 1 — Shingling. Split each prompt into overlapping 3-character shingles (trigrams):
A shingles: {"a m", " ma", "maj", "aje", "jes", "est", "sti", "tic", ...}
B shingles: {"a m", " ma", "maj", "aje", "jes", "est", "sti", "tic", ..., " 4k"}
A produces 64 shingles, B produces 68. They share 64 shingles — B just adds the ones covering ", 4k".
Step 2 — MinHash signature. Apply 128 independent hash functions to each shingle set. For each hash function, record the minimum hash value across all shingles. This compresses each set into a fixed-length signature of 128 integers. Two sets with high overlap will produce similar signatures, because the minimum hash value is likely to come from a shared shingle.
sig(A) = [14, 83, 7, 241, ...] (128 values)
sig(B) = [14, 83, 7, 241, ...] (mostly identical)
Step 3 — LSH banding. Split each 128-value signature into bands (e.g., 16 bands of 8 values). If any band is identical between two prompts, they become candidates for comparison. This avoids comparing all $O(N^2)$ pairs — only prompts that land in the same LSH bucket are checked.
Step 4 — Jaccard estimation. For candidate pairs, estimate Jaccard similarity as the fraction of signature positions that match: $J \approx \frac{\text{matching positions}}{128}$. A and B match on ~120/128 positions → $J \approx 0.94$, well above the 0.7 threshold. They’re flagged as duplicates, and the quality scorer picks A (B’s extra ", 4k" adds no semantic value).
| Input | Output | Removed | Time |
|---|---|---|---|
| 970,030 | 767,995 | 202,035 (20.8%) | ~37 min |
DiffusionDB alone went from 300K to 151K — half its prompts were near-duplicates.
Stage 2: Semantic dedup (FAISS clustering)
MinHash misses paraphrases: “a cute cat watching a movie in a cinema” and “an adorable cat sitting in a movie theater” have low surface overlap but describe the same scene. Semantic dedup catches these.
We embed all 768K surviving prompts with all-MiniLM-L6-v2 via raw PyTorch (not sentence-transformers, which was 5x slower due to internal preprocessing overhead). Then FAISS k-means clusters the embeddings into 876 groups ($\approx\sqrt{N}$), and within each cluster, pairs with cosine similarity above 0.90 are deduplicated.
| Input | Output | Removed | Time |
|---|---|---|---|
| 767,995 | 630,099 | 137,896 (18.0%) | ~2.8 hours (embedding) + ~3 min (clustering) |
The 0.90 cosine threshold was chosen to catch same-scene paraphrases while preserving same-subject-different-scene diversity. At 0.85 it was too aggressive — “a cat in a cinema” and “a kitten watching TV on a couch” are different training signals.
Total dedup: 970K → 630K (35% removed) in about 3.5 hours on CPU. After balance enforcement (Section 5), the final count is 526,915 — the 15% subject cap accounts for most of the additional reduction. With duplicates removed, the next challenge is ensuring these 630K prompts are correctly classified across the taxonomy.
4. Classification: From Keywords to Hybrid
Every prompt needs classification into a MECE (Mutually Exclusive, Collectively Exhaustive) taxonomy (14 Subjects x 7 Styles x 8 Cameras) to measure and enforce coverage. This went through three iterations, each fixing failures revealed by the previous one.

Attempt 1: Keyword matching
The first classifier matched keywords against category dictionaries. It failed predictably:
- “A woman wearing a red dress in a garden” → hits “dress” → Fashion (S9) instead of People (S1)
- “The image displays a promotional flyer with a bird logo” → hits “bird” → Animals (S2) instead of Text/Typography (S11)
- 67% of prompts defaulted to Photorealistic (T1) because implicit styles don’t match keyword lists
- 10% defaulted to Objects (S10) as a catch-all
Keywords are high-precision when they match the right thing, but low-recall — most prompts don’t contain the right keywords, and many contain misleading ones.
Attempt 2: Zero-shot embedding fallback
The fix: use keywords as a first pass, and fall back to zero-shot embedding similarity when keywords return the default label. Each category gets 3-6 natural language descriptions (e.g., S2/Animals: “an animal, dog, cat, bird, wildlife, pet”), embedded with all-MiniLM-L6-v2 and averaged into label centroids. Unmatched prompts are assigned to the nearest centroid by cosine similarity.
Three problems emerged:
Close-call reclassification. Without a confidence threshold, zero-shot reclassifies on differences of 0.01 cosine similarity — essentially random. Fix: a margin threshold of 0.05 — zero-shot must beat the default by at least 0.05 to override.
Vague categories become dumping grounds. GraphicDesign (T6) and Mixed/Experimental (T7) have descriptions broad enough to attract any formal-register text. DenseFusion captions like “The image displays a bowl of fruit…” are semantically closer to “graphic design brief” than “casual photo description” in MiniLM’s embedding space. T6 ballooned to 18.5%, T7 to 24.6%. Fix: keyword gating — zero-shot can only assign T6 or T7 if the text contains explicit design/experimental keywords (“poster”, “infographic”, “glitch”, “collage”).
Weak keyword triggers. Words like “minimal”, “flat”, “logo” appear in scene descriptions (“minimal wear on the surface”, “flat terrain”, “Volkswagen logo on the jersey”) but triggered T6. Fix: treat these as weak keywords that only count when combined with other design signals.
After these fixes, T6 dropped from 18.5% to 4.7%, T7 stabilized at 1.5%, and S10 (the default catch-all) dropped from 10.1% to 2.9%.
Attempt 3: Caption first-sentence stripping
The hybrid approach still had a critical flaw: keyword classification on full VLM captions is unreliable for ALL categories, not just defaults. VLM-generated captions are verbose and mention many objects incidentally:
- “The image displays a green hoodie… worn by a person” → keyword matches “person” → S1 (People). Wrong — subject is the hoodie.
- “The image displays a slide… about a car recall” → keyword matches “car” → S7 (Vehicles). Wrong — subject is the slide.
DenseFusion was classified 60% People by keywords. Manual inspection showed most were objects, graphics, and clothing that happened to mention a person in passing.
The fix: for prompts matching the VLM pattern "The image displays/shows/features/captures...", strip the prefix, extract the first sentence only, and classify that. VLM captions follow a consistent structure — the first sentence names the primary subject, and subsequent sentences describe context, details, and incidental elements.
Validation on 200 DenseFusion samples: People dropped from 58% to 17% (verified genuine), Animals from 26% to 1% (the keyword classifier had been matching “bird”, “fish”, “cat” in logos, book titles, and metaphors).
Non-VLM prompts (DiffusionDB user prompts, JourneyDB Midjourney prompts) still use the standard hybrid approach since they don’t have the descriptive prefix structure.
5. Enforcing Balance
Classification alone doesn’t guarantee a balanced dataset. Two additional enforcement mechanisms:
Subject percentage cap
Without a cap, People (S1) dominates at 30-50% — most image datasets are human-centric. A 15% per-subject cap ensures the student model sees diverse content during training. Subjects exceeding the cap are randomly downsampled; small subjects keep all their prompts.
Chinese prompt minimum length
Short Chinese captions (product names, single phrases) lack enough context for T2I generation. The minimum was raised from 10 to 20 characters.
Length filtering
English prompts outside the 8-200 word range are dropped. The upper bound is higher than the original 12K pipeline (which used 80) because VLM captions from DenseFusion and ShareGPT4V are naturally verbose — and that verbosity is a feature for training prompt adherence.
6. The Final Dataset
data/train/metadata.json — 526,915 prompts (337 MB)
data/debug/metadata.json — 98 prompts (1 per Subject×Style cell)
Validation results:
| Metric | Value |
|---|---|
| Total prompts | 526,915 |
| All 98 Subject x Style cells populated | Yes |
| Language split | EN 97.8% (515,509), ZH 2.2% (11,406) |
| Mean EN word count | 96.5 |
| Median EN word count | 88 |
| Categories | 14 Subjects x 7 Styles |
| Sources | 9 |
| Exact duplicates | 0 |
The mean word count (96.5) is higher than the original 12K dataset (35) because VLM captions from DenseFusion, ShareGPT4V, and Recap-DataComp are naturally verbose. For LADD training, this is beneficial — long, detailed prompts stress-test the student’s prompt adherence more aggressively.
Dashboard
The interactive HTML dashboard provides a complete profile of the final dataset.
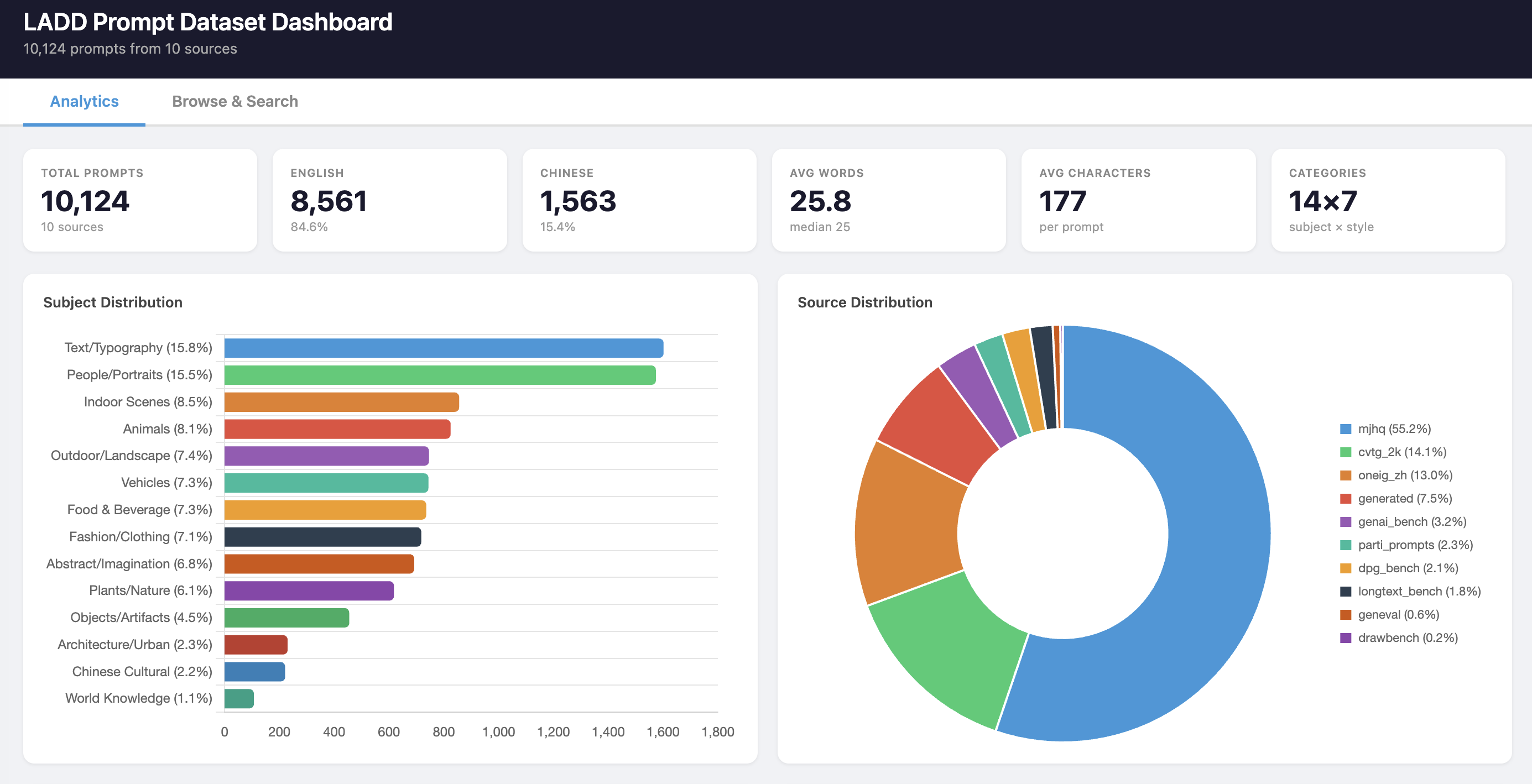
People/Portraits (17.8%) and Text/Typography (14.0%) are the largest subjects. The 15% subject cap reduced People from its original 30-50% dominance; it slightly exceeds 15% in the final dataset because the cap was applied before downstream filtering (Chinese length filter, etc.) shifted the relative proportions. DenseFusion (25.3%) and recap_datacomp (22.3%) contribute the most prompts.
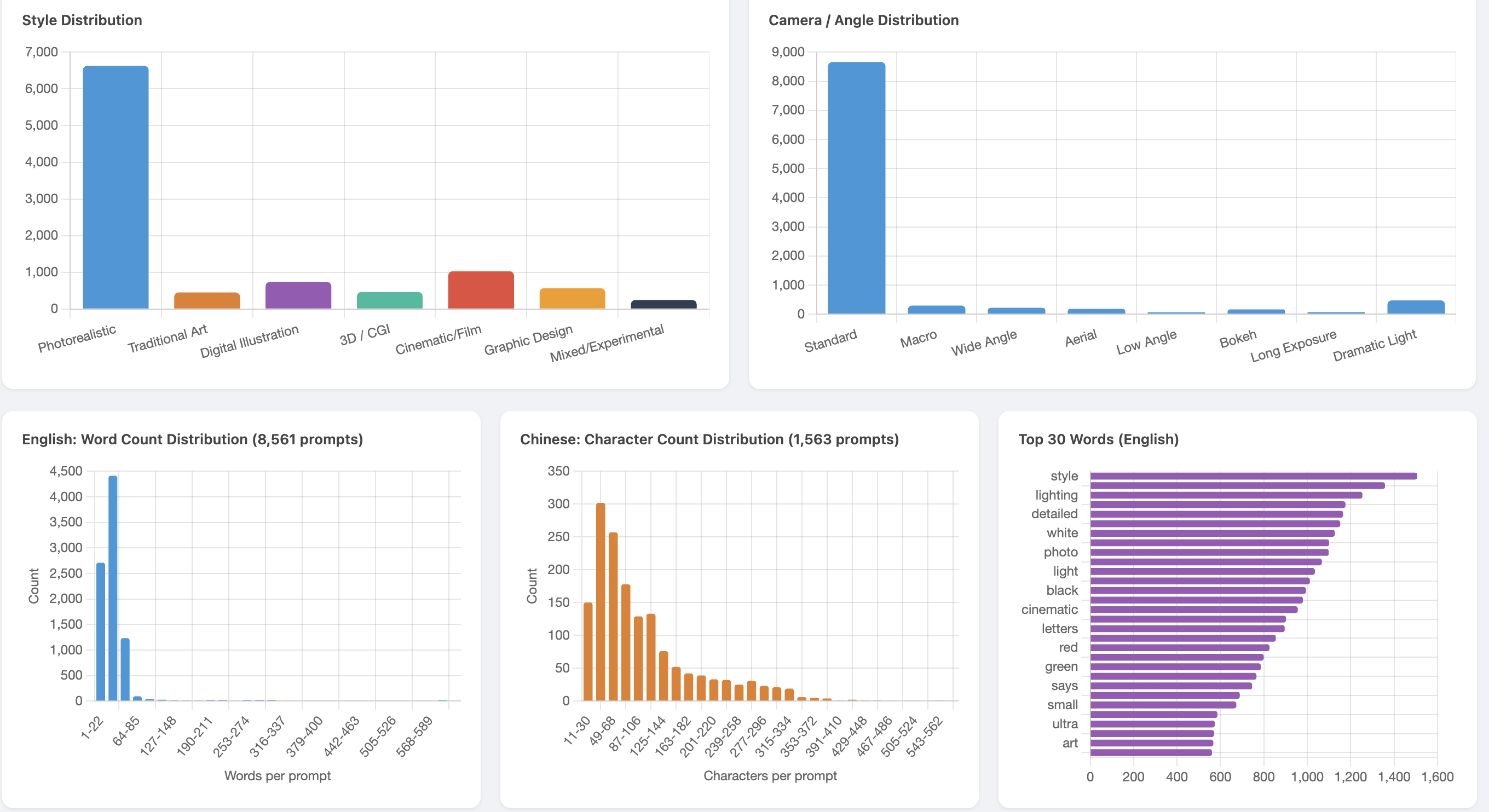
Photorealistic dominates style (74.6%) as expected for a general-purpose T2I model. The English word count distribution shows a bimodal pattern — short user prompts from DiffusionDB/JourneyDB and long VLM captions from DenseFusion/ShareGPT4V.
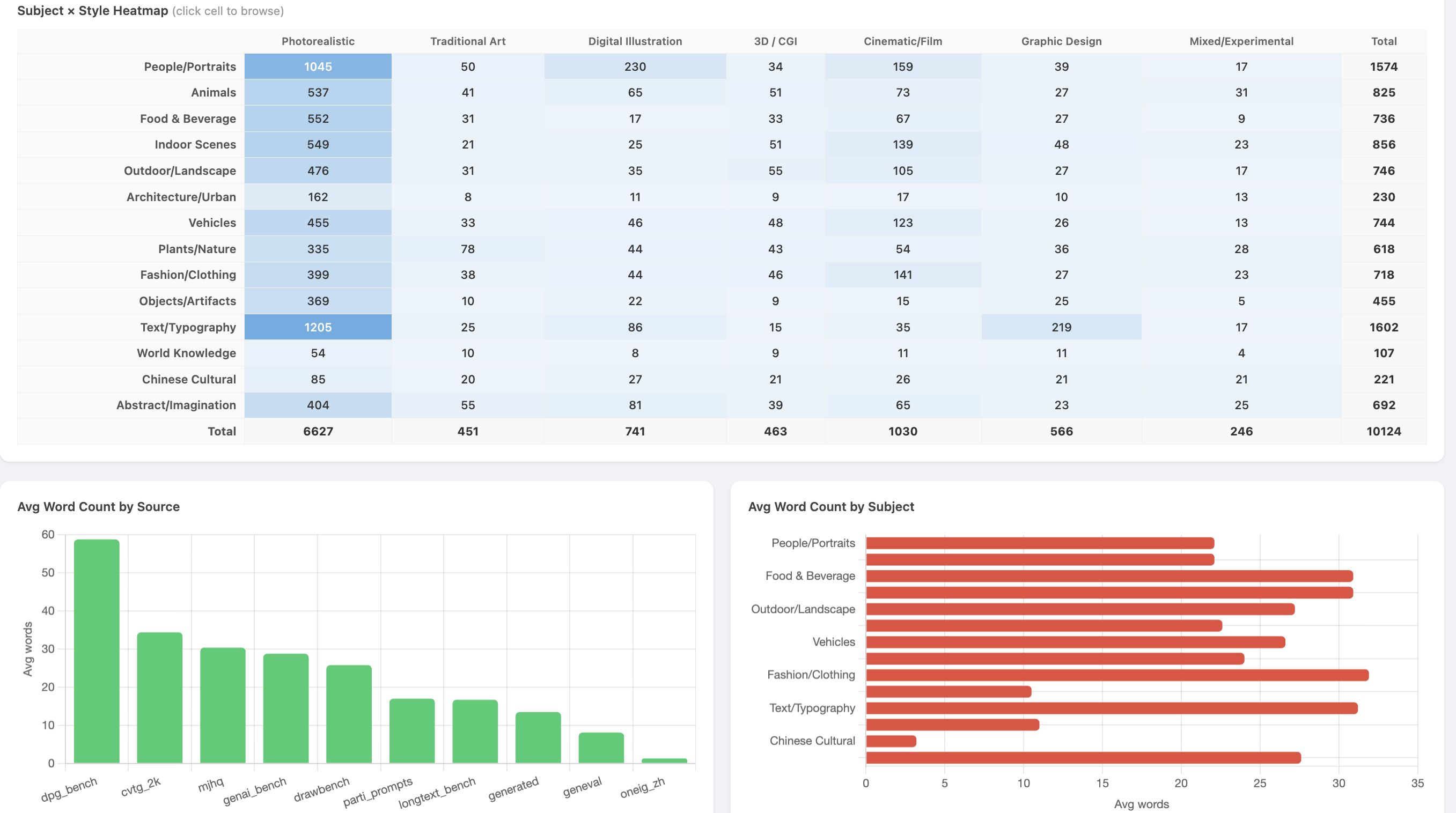
The heatmap confirms all 98 cells are populated. People x Photorealistic (78,806) is the densest cell; sparse cells like Chinese Cultural x Mixed/Experimental (29) reflect genuinely rare combinations rather than classification failures.
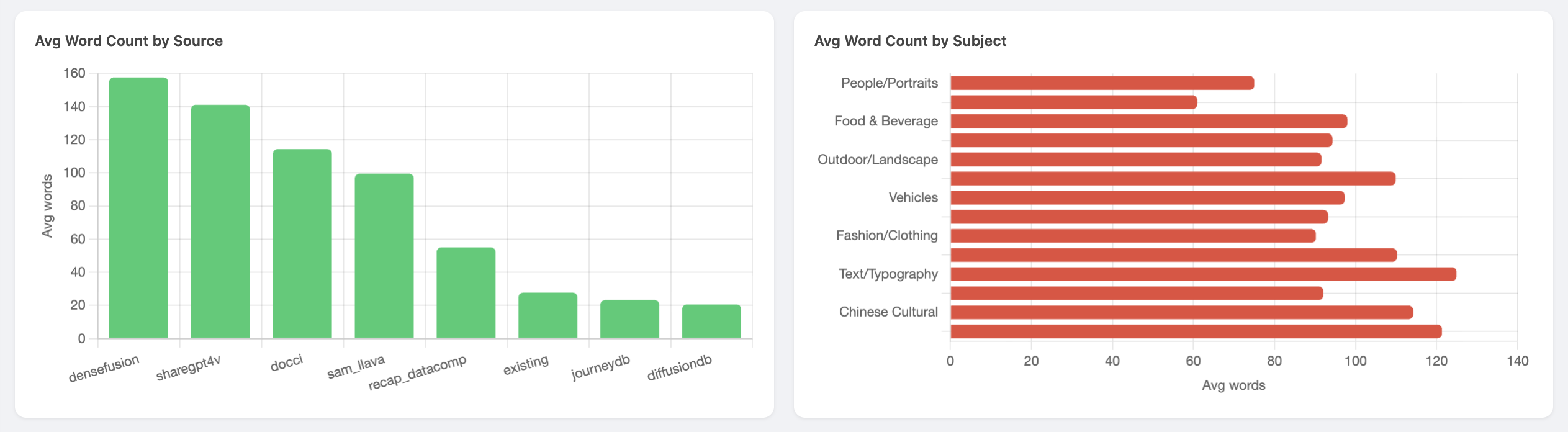
DenseFusion averages ~158 words per prompt — 7x longer than DiffusionDB (~21 words). This length diversity is intentional: short prompts test basic generation quality while long prompts stress-test prompt adherence.
t-SNE Embedding Visualization
To verify that the taxonomy reflects genuine semantic structure (not just keyword artifacts), we embedded 50K sampled prompts with all-MiniLM-L6-v2 and projected them to 2D with t-SNE.
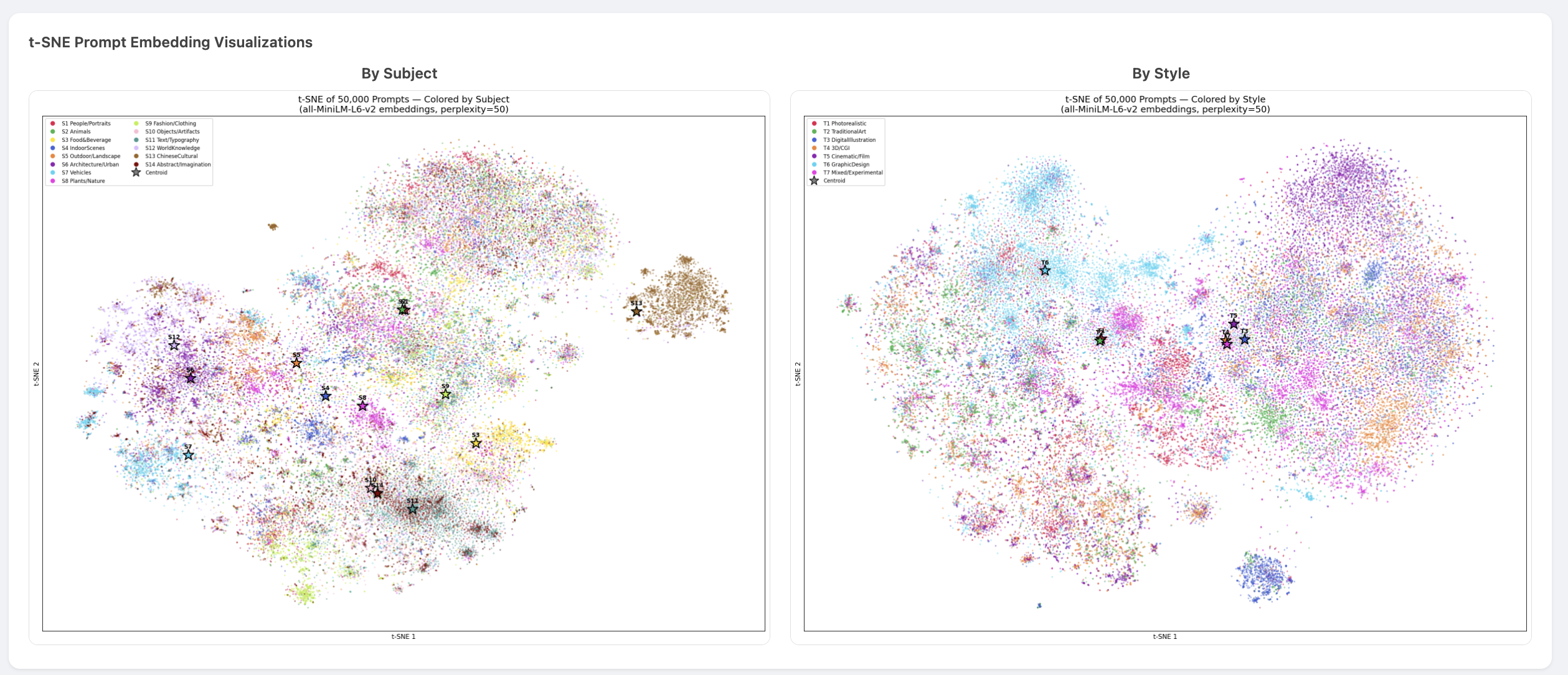
The subject view (left) shows clear clustering — Animals, Vehicles, Text/Typography, and Chinese Cultural form distinct islands, confirming the classifier captures real semantic boundaries. The style view (right) shows more overlap, which is expected: style is orthogonal to content and harder to separate in embedding space.
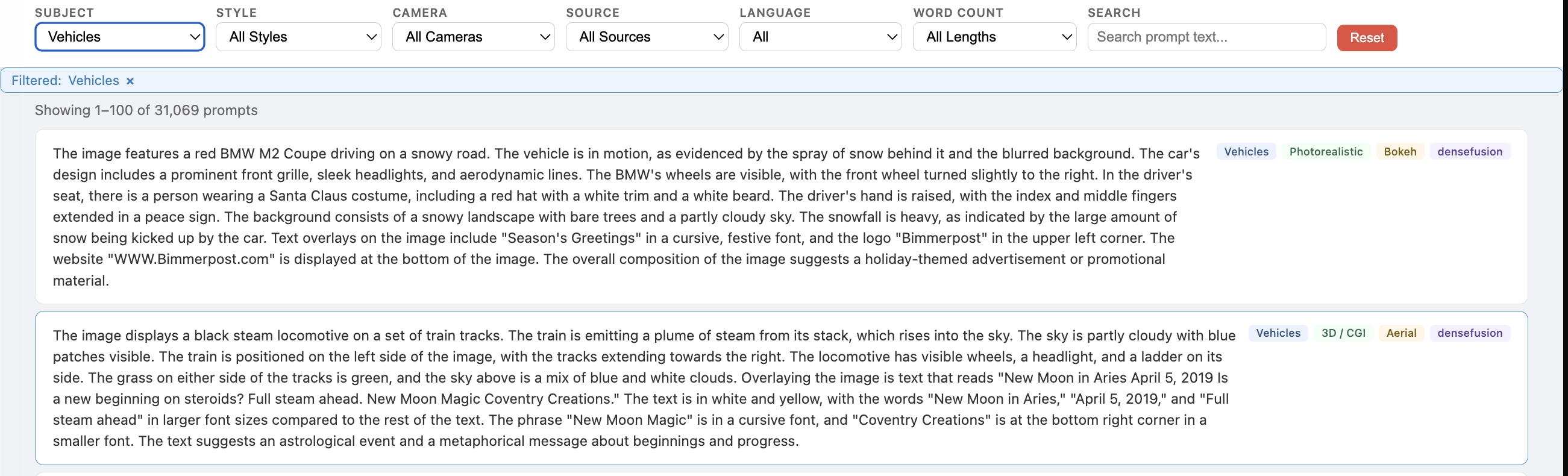
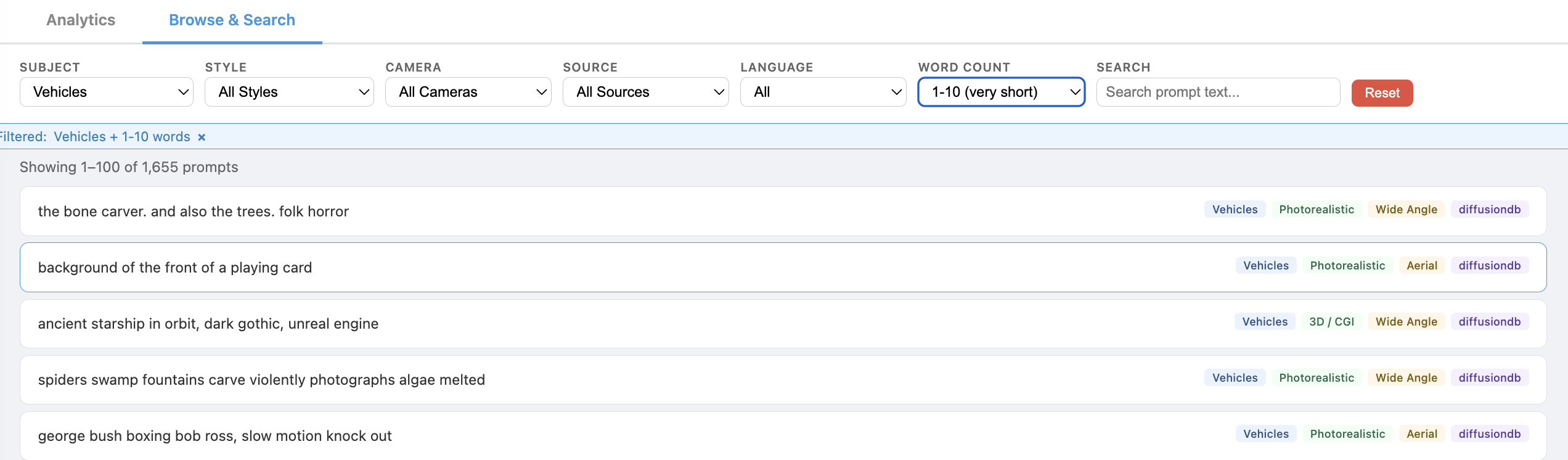
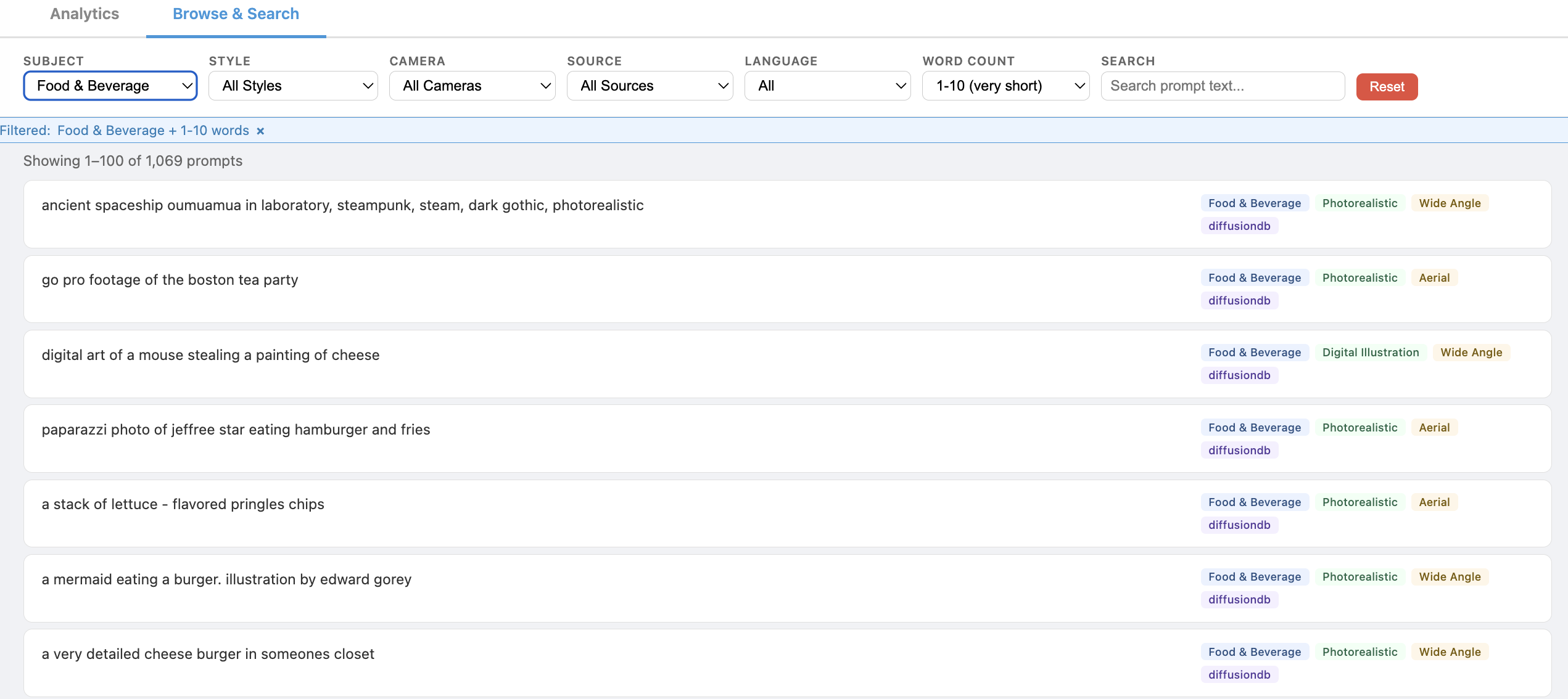
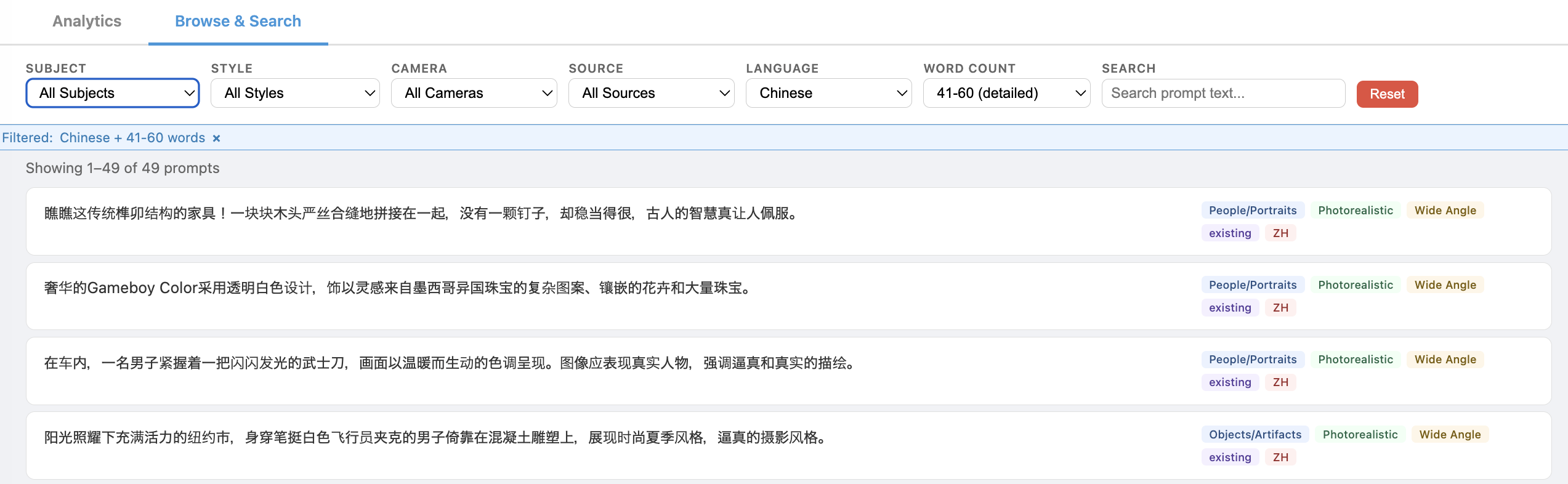
Browse & Search
The dashboard includes an interactive browser for inspecting individual prompts with filtering by subject, style, camera, source, language, and word count.
Pipeline scripts
The pipeline is five scripts, each idempotent (skip sources that already have output files):
| Script | Purpose |
|---|---|
harvest.py |
Download, filter, and normalize all sources to data/raw/*.jsonl |
dedup_minhash.py |
MinHash LSH surface dedup |
dedup_semantic.py |
Embedding + FAISS clustering + pairwise semantic dedup |
classify_and_sample.py |
Hybrid keyword+zero-shot classification into taxonomy |
build_dataset.py |
Length filter, subject cap, validation checks, debug split |
Gap to 1M
We’re ~470K prompts short of the original 1M target. Options: LLM generation to fill sparse cells, additional sources (COYO-700M, CC3M/CC12M, TextCaps), or accept 527K — at batch size 256 and 10K iterations, each prompt is seen ~5 times on average, which is still viable for training.
7. Lessons Learned
Classification
Keyword classification is unreliable for ambiguous prompts and verbose captions. Keywords are high-precision when they match correctly, but 67% of prompts fall through to defaults. Semantic classification is worth the cost for smaller datasets; at scale, a hybrid approach combines keyword precision with zero-shot recall.
Zero-shot embedding classification confuses register with content. MiniLM places formal descriptive captions (“The image displays…”) closer to design briefs than to casual photo descriptions. Pure zero-shot precision for GraphicDesign was ~50%. Domain-specific keyword gating brought it above 90%.
Vague categories become dumping grounds. Any category with broad descriptions (GraphicDesign, Mixed/Experimental) will attract the long tail of ambiguous prompts. Keyword gating prevents this — require explicit evidence before assigning to catch-all categories.
Classify the primary subject, not the full text. VLM captions mention many objects incidentally. A caption about a hoodie that mentions “worn by a person” is not a People prompt. Stripping to the first sentence fixes this for VLM-generated captions; user-written prompts don’t have the problem.
Deduplication
MinHash LSH is the workhorse. It caught 21% of duplicates in 37 minutes. Semantic dedup adds value (18% more) but takes 10x longer. If time-constrained, MinHash alone gets you 80% of the way.
sentence-transformers adds significant overhead on CPU. Raw transformers + manual mean-pooling was 5x faster for the same model (~73 prompts/sec vs ~12/sec). The library is convenient but not built for batch throughput.
Data sourcing
HuggingFace dataset IDs are unstable. Three of 10 datasets had wrong or outdated org names. The datasets library broke backward compatibility in v4.8+ — dataset scripts with trust_remote_code are no longer supported. Always verify IDs and have a fallback to direct parquet or JSONL loading.
Schema mismatches across parquet shards are real. Recap-DataComp-1B had different columns in different shards. Loading individual shards instead of the whole dataset was the workaround.
Balance
Source diversity matters more than volume. 10K well-balanced prompts from 9 sources produces better training coverage than 30K dominated by one source.
Subject balance requires explicit enforcement. Without a per-subject cap, People dominates at 30-50% because most image datasets are human-centric. A 15% cap ensures the student sees diverse content.
Chinese prompts need separate handling. Word-count filters don’t apply (Chinese uses characters), and CJK detection is needed for language tagging. The minimum character threshold matters — short Chinese captions are too vague for T2I generation.
Appendix: Download Reality vs. Documentation
Half the datasets required workarounds that weren’t in any README:
- DiffusionDB: dataset script no longer supported by
datasetsv4.8+; loadedmetadata-large.parquetdirectly - Recap-DataComp-1B: different parquet shards have different column schemas; loading individual shards bypasses the
CastError - DenseFusion-1M: the plan had the wrong HuggingFace org (
DenseFusion/→ actuallyBAAI/), and required the config name"DenseFusion-1M" - ShareGPT4V-PT: config
"ShareGPT4V-PT"doesn’t exist; the default loads the 1.2M PT set as multi-turn conversations; prompts are the assistant’s first reply - JourneyDB: gated and can’t stream; downloaded
train_anno.jsonl.tgzviahf_hub_downloadand extracted locally - DOCCI:
trust_remote_coderejected by moderndatasets; downloaded JSONL directly from Google Cloud Storage - Wukong:
noah-wukong/wukongreturns 404;wanng/wukong100mhas the captions