Discovering New Scenarios in Waymo's 'Others' Bucket — Two Captioners, One Surviving Cluster
April 28, 2026
Target audience: ML practitioners following the previous post on VLM-as-judge for Waymo E2E. This is the standalone follow-up that demonstrates the novel-scenario candidate route in Section 9’s triage funnel.
Why this question matters
The previous post’s triage funnel had three downstream routes for clips a video VLM judge processes: auto-bin when uncertainty is low and judges agree, standard human review when uncertainty is high or judges disagree, and novel-scenario candidate when no judge is confident and the predicted distribution is roughly uniform across multiple non-default classes — the operational signal that the clip might not fit any of the existing 10 Waymo categories cleanly.
That third route was specified but not demonstrated. This post demonstrates it on the most natural starting point: Waymo’s Others cluster, the catch-all in their 10-class taxonomy. The hypothesis is simple: clips Waymo labeled Others shouldn’t all be the same kind of “doesn’t fit anywhere else.” If a captioning VLM can describe each clip and we cluster the captions semantically, the dense regions of caption space should correspond to discoverable sub-categories Waymo could promote to first-class taxonomy entries.
The operational payoff if it works: a learned-eval pipeline can flag specific clips for taxonomy review, not just generic human review.
Why two captioners, not one
The obvious single-captioner version of this experiment is also the obvious failure mode: cluster structure that looks meaningful but is just an artifact of one model’s stylistic patterns. If Cosmos-Reason 2 always opens captions with “The scene unfolds…” and Molmo always opens with “The vehicle is…”, a dumb clusterer might find dense regions just on the opening phrase.
To gate against this, we run two independent captioners — Cosmos-Reason 2-2B and Molmo2-8B, both with native video understanding, both with observably different output styles in the previous post’s experiments. We caption each clip with each captioner, embed each captioner’s outputs separately, cluster each separately, and then ask: do the two captioners independently put the same clips together?
Cluster pairs that emerge from BOTH captioners are the trustworthy discoveries. Cluster pairs that only one captioner finds are likely captioner artifacts. Cross-captioner agreement is the methodological gate.
This is also the load-bearing answer to a critical-reviewer question: even if both captioners share web-data training distribution and aren’t fully independent, agreement between two models with different decoder behavior is better evidence than a single model’s confident clustering.
Setup
| Step | What | Why |
|---|---|---|
| Data | All 22 Others-labeled sequences in WOD-E2E val (8-camera composites at 4 Hz, 32 frames each) |
Every Others clip in val. We did not sample. |
| Captioning | Cosmos and Molmo each generate N=3 stochastic captions per clip (temperature=0.5, max_new_tokens=200) |
Lets us measure within-captioner stability before claiming cross-captioner agreement is meaningful. |
| Embedding | sentence-transformers/all-MiniLM-L6-v2 on each caption; mean-pool the 3 embeddings per (clip, captioner) |
Standard, fast, no API. |
| Clustering | HDBSCAN (min_cluster_size=3, min_samples=2) on the mean embeddings, per captioner |
Density-based — no need to specify K, naturally produces “noise” points (clips that don’t fit any dense region). |
| Cross-captioner agreement | ARI + NMI between the two cluster assignments + Hungarian bipartite matching on per-cluster Jaccard overlap of clip-set membership | ARI/NMI are label-permutation-invariant by construction. Hungarian matching finds the canonical Cosmos-cluster ↔ Molmo-cluster correspondence by clip overlap, not by label. |
| Significance | $B = 1000$ permutation null on ARI, NMI, and per-cluster max-Jaccard | Converts “ARI = 0.16” from an arbitrary number into “ARI = 0.16 with $p$ under permutation.” |
The captioning prompt was identical for both models:
“Describe this autonomous-vehicle scenario in 2-3 concrete sentences. Focus on: (1) what kind of road and environment, (2) what the safety-relevant agents are doing, (3) any unusual or interesting elements that distinguish this clip from typical driving footage. Do not name a category or label — just describe what you see.”
The “do not name a category” line is deliberate — we don’t want the captioner to leak Waymo’s taxonomy vocabulary into the captions and have the clusterer find it.
Honest size note
WOD-E2E val has 22 Others clips total. With $N = 22$ and HDBSCAN’s min_cluster_size=3, this study is at the lower end of what unsupervised clustering can meaningfully do — there’s room for at most ~7 clusters and the per-cluster sample sizes will be small. The previous post planned for ~60 clips; the actual count came in lower. We ran the experiment honestly with what’s available rather than artificially augmenting from other clusters, since the question is specifically about the Others bucket. Treat the per-cluster numbers as suggestive rather than tight.
What each captioner found
After embedding and clustering, here is the per-captioner UMAP projection. Same clips, two captioners, two independent clusterings:
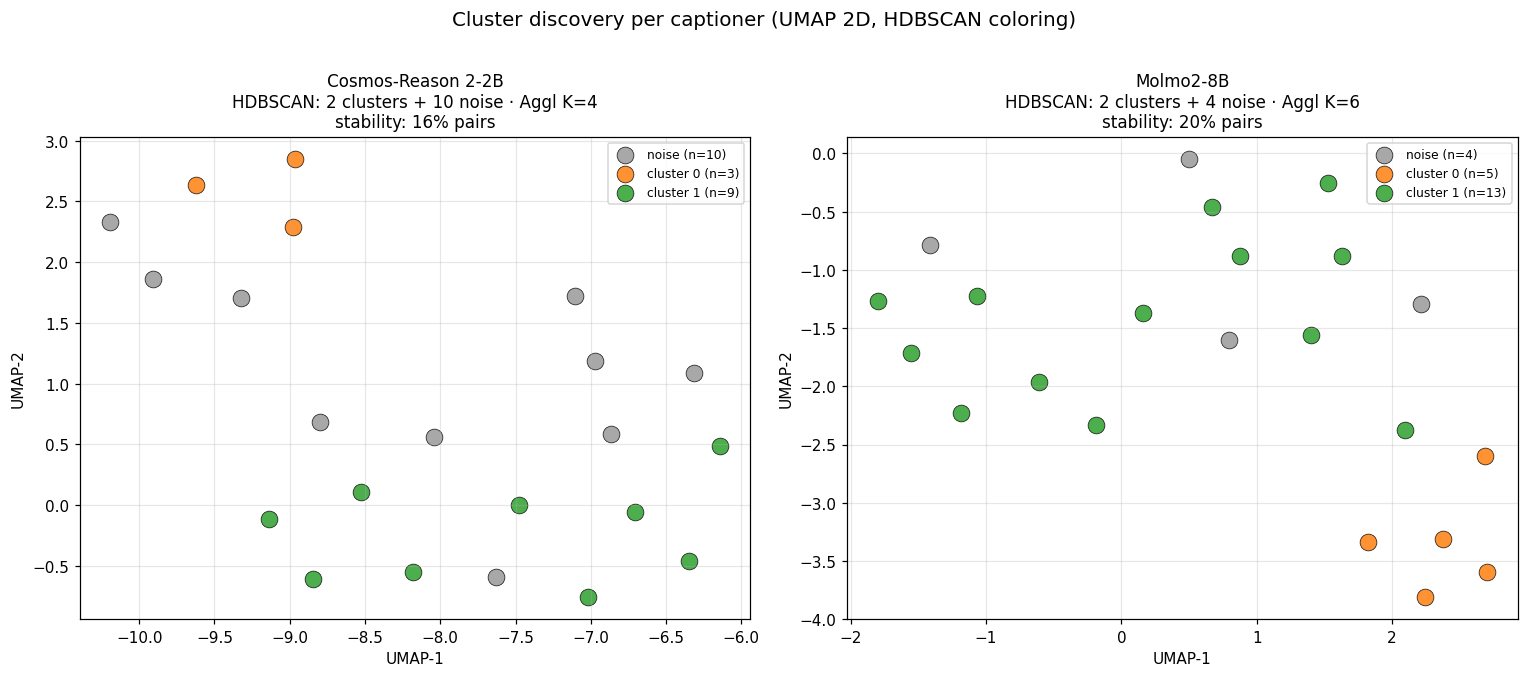
Per-captioner summary:
| Captioner | HDBSCAN clusters | Noise points | Agglomerative (silhouette-K) | Within-captioner pair stability |
|---|---|---|---|---|
| Cosmos-Reason 2-2B | 2 | 10 / 22 | K=4 | 15.6% |
| Molmo2-8B | 2 | 4 / 22 | K=6 | 20.4% |
Two things are worth flagging immediately:
- Cosmos has many more noise points than Molmo. Cosmos rejects 10 / 22 clips as not fitting any dense region; Molmo rejects 4. This is consistent with Cosmos producing more uniformly verbose captions (every clip becomes a long descriptive paragraph), making the embedding space more diffuse. Molmo’s terser, more variable captions cluster more tightly.
- Within-captioner stability is low (15-20% of clip pairs co-clustered in a majority of the 3 stochastic-caption runs). With only $N = 22$ clips and 3 caption runs per clip, the floor is noisy. This is the small-sample tax we pay for running on the actual
Othersset rather than a larger augmented one.
Neither finding sinks the experiment, but both shape what cross-captioner agreement would have to look like to be defensible.
Cross-captioner agreement
The whole point of the two-captioner design is the next plot. Left panel: the per-cluster Jaccard matrix on clip-set membership (rows = Cosmos clusters, columns = Molmo clusters). Hungarian bipartite matching picks the unique 1-to-1 pairing of Cosmos clusters to Molmo clusters that maximizes total Jaccard. Right panel: the permutation-null distribution of ARI ($B = 1000$ random label shuffles), with the observed value marked.
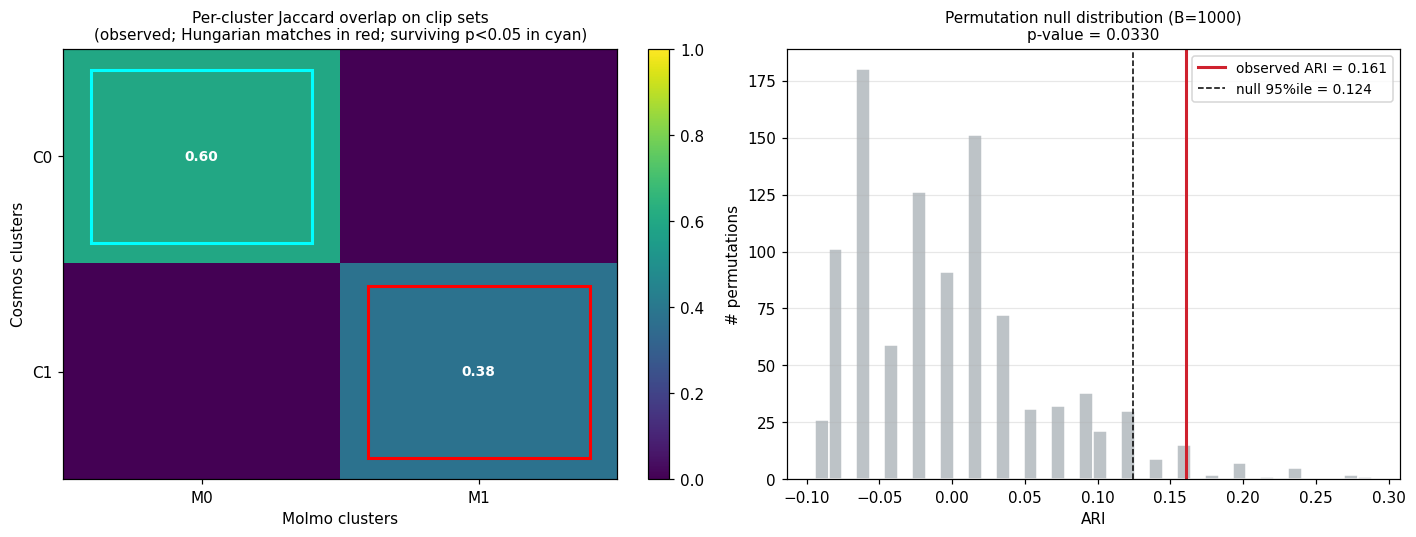
The headline numbers:
| Metric | Observed | Permutation null | Interpretation |
|---|---|---|---|
| ARI (Cosmos vs Molmo) | 0.161 | mean 0.000 ± 0.066, 95%ile 0.124, p = 0.033 | Above chance |
| NMI | 0.341 | mean 0.116 ± 0.070, 95%ile 0.254 | Above chance |
| Max per-cluster Jaccard | 0.60 | 95%ile 0.467 | Above the per-cluster significance threshold |
| Surviving cluster pairs | 1 of 2 | — | Cosmos cluster 0 ↔ Molmo cluster 0 (Jaccard 0.60) survives; the second matched pair (Jaccard 0.375) is at-or-below random |
So the cross-captioner agreement is real but modest, and it concentrates in one specific cluster pair rather than uniformly across the whole partition. The other matched pair — the larger “generic urban driving” lump — has a Jaccard match of 0.375, below the 0.467 95-percentile null threshold, meaning that pair’s overlap is no better than what we’d see by random chance. The agreement here is category-specific, not diffuse.
The one surviving discovery: nighttime / low-light driving
The single significant cross-captioner cluster pair is Cosmos cluster 0 (3 clips) ↔ Molmo cluster 0 (5 clips), with 3 clips in the intersection (9b0d28378699, 9e4afa858b13, c2b5c5e7dcfd). The full union of 5 clips: 1c2695b6dc58, 4fe50a077365, 9b0d28378699, 9e4afa858b13, c2b5c5e7dcfd.
A general-purpose subagent given both captioners’ captions for these clips — and told they had been independently grouped by the clustering and survived a permutation-test gate — proposed:
Nighttime Street Driving — Ego vehicle navigating dimly lit urban or residential streets at night where streetlights, headlights, and building lights provide the primary illumination.
Confidence: high. Key signals: nighttime/dark setting mentioned by both captioners; streetlight/headlight illumination as primary light source; urban or residential street context.
Two of the agreed clips, exactly as the captioners saw them:
Sample captions (1 per captioner per clip, both captioners independently):
| Clip | Cosmos | Molmo |
|---|---|---|
9b0d28378699 |
“The scene unfolds at night on a dimly lit residential street, where the road is illuminated by streetlights and vehicle headlights…” | “The vehicle is driving on a dark, wet road at night with limited visibility. Other vehicles are traveling in both directions…” |
9e4afa858b13 |
“The scene unfolds on a dimly lit, two-way road at night, with the primary illumination coming from streetlights…” | “The vehicle is traveling on a two-lane road at night, passing through a residential area with houses and parked cars…” |
c2b5c5e7dcfd |
“The scene unfolds on a dimly lit road at night, where the primary source of illumination comes from the headlights of a vehicle approaching…” | “The vehicle is traveling on a dark, two-lane road at night, with minimal ambient lighting…” |
Why this is more interesting than it looks
The discovery is operationally modest — one sub-cluster, 5 clips, “nighttime driving” — but it lands in a methodologically meaningful place: Nighttime Street Driving is not the kind of category Waymo’s existing 10 are.
Waymo’s taxonomy is agent/event-driven: Cyclist, Pedestrian, Cut_in, Construction, Foreign Object Debris, Special Vehicles. These categories say what kind of safety-relevant event the clip contains. “Nighttime Street Driving” doesn’t say what’s happening — it says what conditions the scene is captured under.
Two readings of this finding, both worth saying out loud:
- The
Othersbucket is partially a “lighting / weather conditions” catch-all, not a “novel scenario types” catch-all. When labelers can’t apply a clean event tag because low light obscures the safety-relevant agent, the clip ends up inOthers. That’s a finding about how the labeling pipeline interacts with conditions, not about a missing event category. - Caption-based discovery is biased toward what captioners can describe well. Both Cosmos and Molmo produce strong, consistent captions about lighting, weather, and street-type — these are the visual features that survive into text. Subtler scenario types (“vehicle making an unprotected left turn into oncoming traffic”; “driver confused by ambiguous lane markings”) are the things captioners struggle with, and exactly the things this method would be most useful for finding. The method works, but it works best on the surface features the captioners already see clearly.
For the operational triage funnel, the practical takeaway is: a “novel-scenario candidate” branch shouldn’t auto-create a new event category from a discovered cluster. It should route to a taxonomy-review queue where a human decides whether the cluster is (a) a missing event type, (b) a missing condition tag, or (c) an artifact of how labelers handle ambiguous clips. The VLM-cluster pipeline does the finding; the human does the judging.
What this round explicitly doesn’t do
- Sample size. 22 clips. The method’s resolution is bounded by what fits in dense HDBSCAN regions of size ≥3 — practically 1-3 surviving cluster pairs.
- Two captioners is not “two independent measurement systems.” Both are open-weights video VLMs trained on overlapping web-scale image/video-text data. Their caption styles differ but their underlying visual feature extractors share substantial inductive bias. A truly independent third opinion (e.g., a frame-level still-image VLM, or human-written captions on the same clips) would strengthen any agreement claim. We did not run that round.
- No fine-tuning. Both captioners are zero-shot. A captioner fine-tuned on Waymo cluster names would presumably surface much sharper sub-clusters in
Others— and would also be much more vulnerable to leaking the taxonomy vocabulary. The right thing to do next is run the same experiment with a third captioner on a larger AV-scenario dataset, not to fine-tune the current ones. - No silhouette / cluster-stability sweep. We picked
min_cluster_size=3once and ran. With more data, sweeping clustering parameters and reporting only clusters that survive across multiple parameter settings would be the right move.
Connection back to the main funnel
In the main post, Section 9 specifies the triage funnel routing rule for “novel-scenario candidate” as: high uncertainty + no judge confident + roughly uniform predicted distribution → flag for taxonomy review. This follow-up corresponds to that route’s downstream step — what to do once a clip lands in the taxonomy-review queue. The answer:
- Caption with at least two independent VLMs.
- Embed and cluster each captioner’s outputs separately.
- Compute cross-captioner agreement with a permutation null.
- Hand only the cluster pairs that survive the per-cluster significance threshold to a human reviewer with subagent-proposed names.
- Surface (a) the proposed name, (b) the agreed-upon clip set, (c) the cross-captioner Jaccard, and (d) the question “is this an event category, a conditions tag, or a labeling artifact?”
The combined pipeline is: VLM judge surfaces candidates → captioner-cluster pipeline proposes structure → human decides the taxonomy implication. No step claims more authority than it has earned.
Artifacts
analysis/inspection_sample.md— Phase B caption quality-gate inspection record (10 clips × 2 captioners × 3 captions)analysis/others_caption_umap_both.png— UMAP scatter per captioneranalysis/others_cross_captioner_overlay.png— Jaccard heatmap + permutation-null histogramanalysis/others_cross_captioner_agreement.json— full ARI/NMI/Jaccard/p-value tableanalysis/others_discovered_categories.json— surviving clusters with subagent-proposed names
Source scripts:
gpu_box_scripts/caption_clips_cosmos.py,caption_clips_molmo.py— captioning pipelines (forked from the VLM-judge scripts)analysis/cluster_others_captions.py— Phase C clustering + within-captioner stabilityanalysis/cross_captioner_agreement.py— Phase D agreement + permutation test