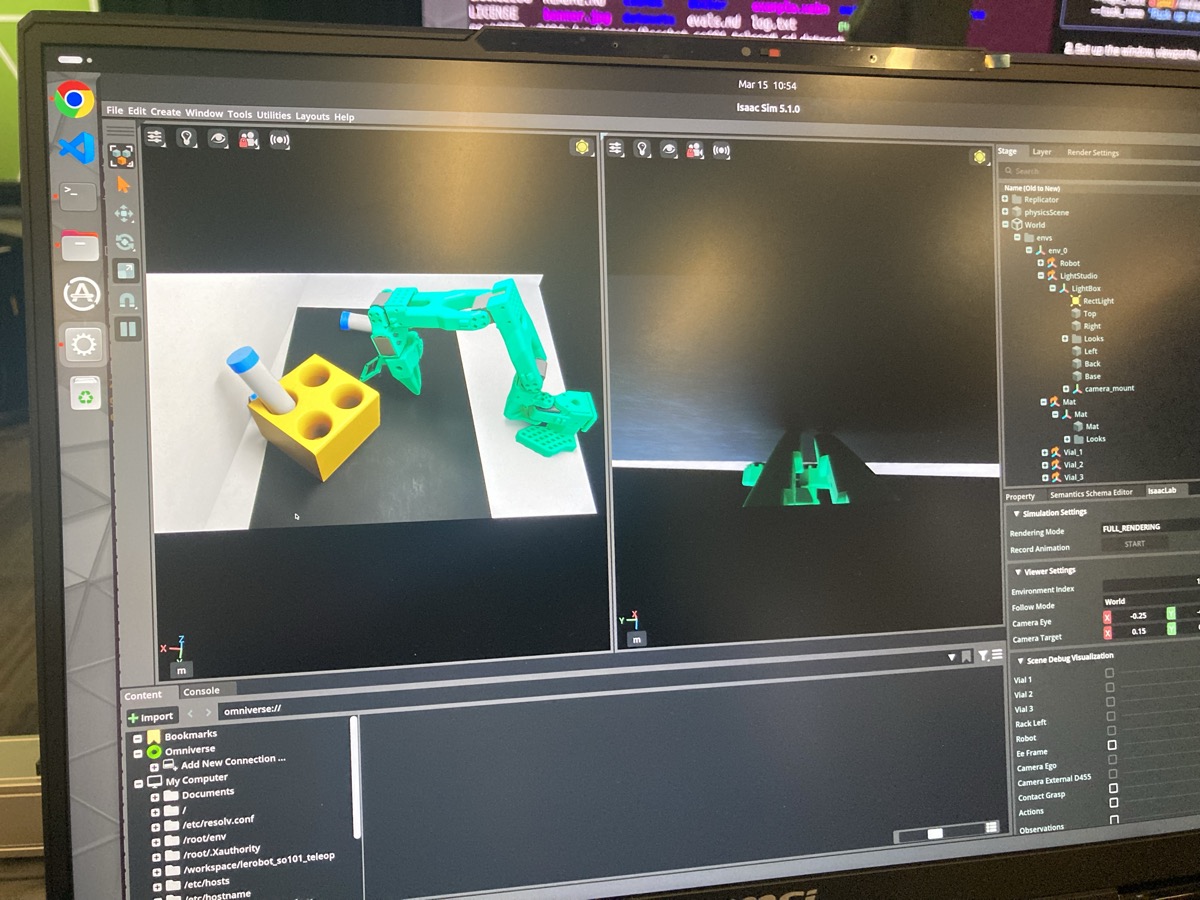
I just came out of an 8-hour robotics workshop at NVIDIA GTC 2026 where we trained a robot arm to pick up centrifuge vials and place them into a rack — first in simulation, then on a real SO-101 robot. This post is part workshop recap, part reflection on how the theory I’ve been studying in CS285 (Deep RL, UC Berkeley) actually plays out when you put a policy on physical hardware.
The Task: Vials into a Rack
The setup was deceptively simple. You have an SO-101 robot arm — a 6-DOF arm with a parallel jaw gripper — sitting inside a white lightbox. On a foam mat in front of it: three centrifuge vials and a yellow rack with four holes. The job? Pick up the vials and place them in the rack.

Simple for a human. Extremely non-trivial for a robot that’s learned entirely from demonstrations.

The workshop walked us through the full pipeline: collecting teleoperation data in simulation, training a Vision-Language-Action (VLA) model using NVIDIA’s GR00T N1.6, evaluating in sim, deploying on hardware, observing the gap, and then systematically closing it. The whole thing was really well-run — the instructors were great, everything was pre-configured (thank god), and everyone in the room was genuinely excited to watch a tiny robot arm fumble with plastic tubes.
The Sim-to-Real Gap
If you’ve taken any robotics or RL course, you already know about the sim-to-real gap — basically, your policy does great in simulation and then falls apart on actual hardware. In CS285, this shows up as distribution shift: the policy was trained on one distribution (simulated), but at test time it encounters a different one (real). It’s never seen real sensor noise, real lighting, or the actual backlash in hobby servos.

The workshop categorized the gap into four buckets — sensing (camera noise, lighting), actuation (motor backlash, friction), physics (contact dynamics, friction coefficients), and modeling (CAD-to-reality mismatches). In practice, all four compound on each other.
Watching this play out on the real robot, I could see the compounding errors that CS285 warns about in behavioral cloning. Small perception errors lead to slightly off actions, which put the robot in states it’s never trained on, which lead to worse actions, and so on. It doesn’t recover because it was never trained on recovery — it only saw expert demonstrations.
What’s a VLA, Anyway?
The core model here is a Vision-Language-Action (VLA) model. Think of it as:
Input: Camera images (wrist + external) + language instruction
"Pick up the vial and place it in the yellow rack"
Output: A chunk of future joint position actions
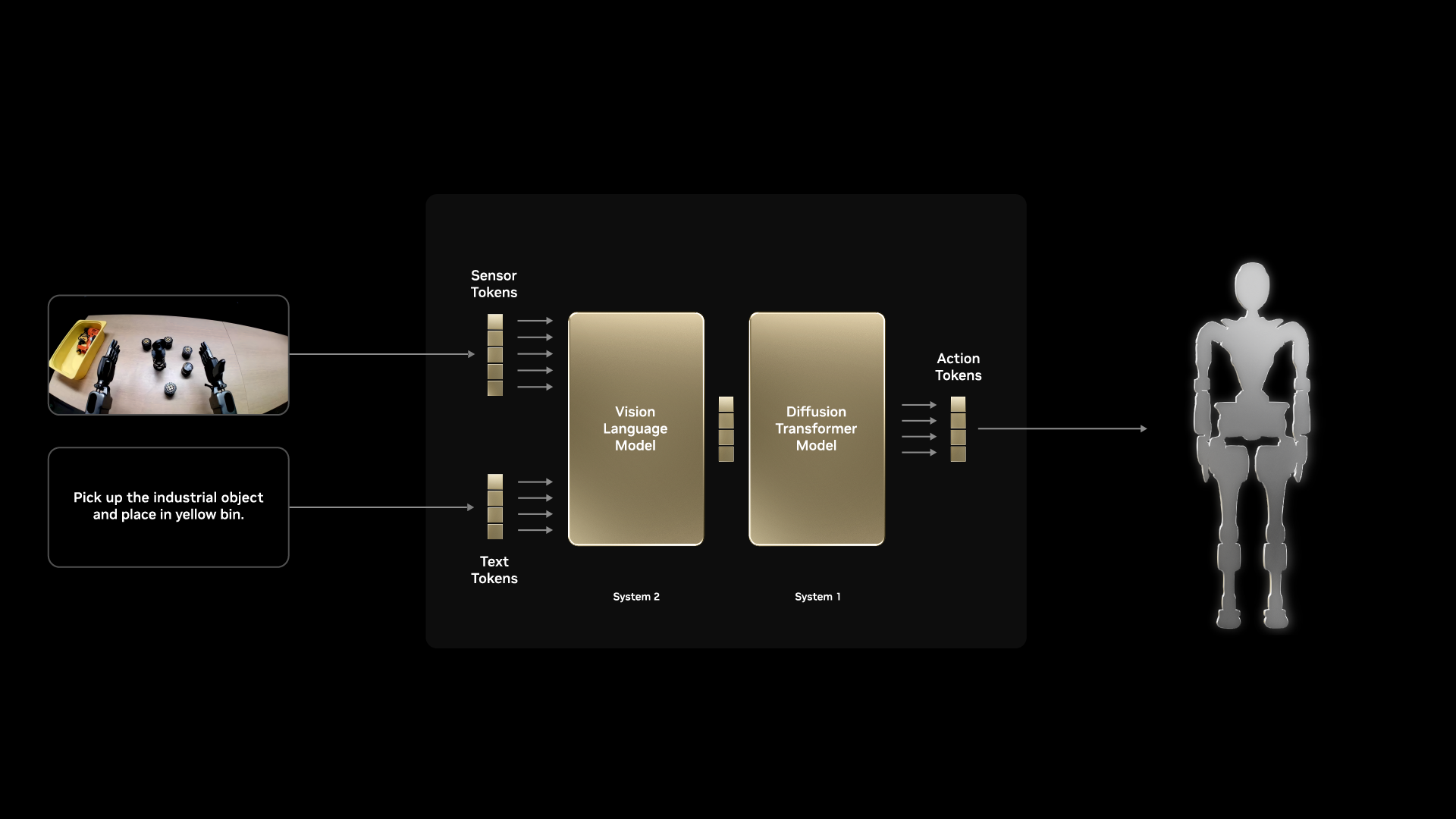
GR00T N1.6 uses a Cosmos-Reason-2B vision-language backbone, 32 DiT (Diffusion Transformer) layers for action generation, and action chunking — predicting 16 future timesteps at once for smoother trajectories.
From a CS285 perspective, this is behavioral cloning at scale. You collect expert demonstrations (via teleoperation), and the model learns a mapping from observations to actions via supervised learning. The VLA architecture adds two powerful ingredients that vanilla BC doesn’t have:
- Pre-trained visual representations — the vision encoder has already seen internet-scale image data, so it doesn’t need to learn “what is a vial” from 50 demonstrations
- Language conditioning — the task is specified in natural language, which in theory enables zero-shot generalization to new instructions
The action chunking is also interesting from a controls perspective. Predicting a short horizon of actions (rather than one at a time) produces smoother, temporally consistent motions — but trades off reactivity. A short action horizon (4-8 steps) is more reactive but jerky; a long one (32+) is smooth but slow to correct mistakes.
Four Strategies to Close the Gap
The workshop structured the afternoon around three progressively more sophisticated strategies (plus a fourth I’ll cover in a future post). Here’s the breakdown.
Strategy 1: Domain Randomization
The idea: instead of making your simulation perfectly match reality, randomize everything — lighting, camera poses, object positions, textures, physics parameters — so the policy becomes robust to any value in the range, including the real-world values.
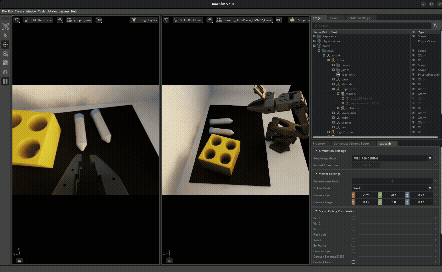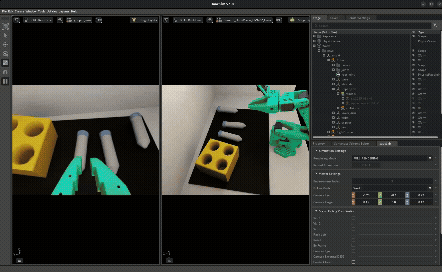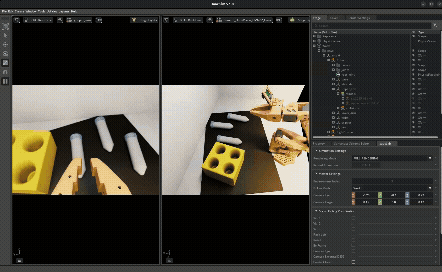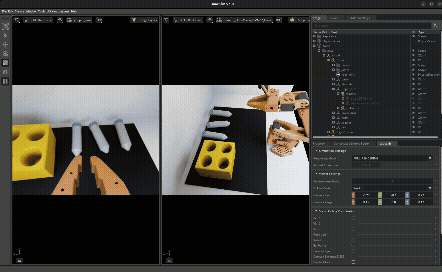
This is effectively data augmentation for the state distribution — you’re broadening the training distribution so that the real-world distribution falls within its support. If your policy has seen lighting from 2000K to 8000K in sim, the 5000K fluorescent tube in the real lab isn’t out-of-distribution anymore.
What gets randomized:
- Lighting intensity, color temperature, HDRI environment maps
- Camera position/orientation offsets
- Object positions (vials and rack placement)
- Probability of vials being pre-placed in slots
The baseline model trained with DR on 75 simulated demonstrations achieved ~50-70% success in simulation. Not bad for a starting point. Here’s an example of some teleop data we recorded — you can visualize it on HuggingFace:
Visualize our teleoperation dataset on HuggingFace
Strategy 2: Co-Training with Real Data
Pure sim data, even with DR, still has a distribution gap. The fix: mix in a small amount of real teleoperation data during training. We’re talking 5-50 real episodes combined with 70-100 sim episodes.
This shares the same motivation as DAgger from CS285 — you need data from the deployment distribution to fix distribution shift. Co-training isn’t DAgger though: DAgger is an iterative, on-policy correction scheme where the expert labels states the learned policy visits. Co-training is simpler — just mixing data sources — but it captures the core insight: some real-world data goes a long way toward anchoring your policy in the right distribution.
| Data Source | Quantity | Reality Match |
|---|---|---|
| Simulation | Abundant, cheap | Approximate |
| Real teleop | Limited, expensive | Exact |
| Combined | Best of both | Better transfer |
Strategy 3: Cosmos Augmentation
Here’s where it gets creative. NVIDIA Cosmos is a world foundation model that can take a robot demonstration video and generate photorealistic variations — different lighting, textures, backgrounds — while preserving the task structure and physics.

Domain randomization can only vary what you explicitly parameterize, and it still looks “synthetic.” Cosmos generates truly diverse, photorealistic training data. We evaluated two variants: 75 sim + 7 Cosmos episodes, and 75 sim + 70 Cosmos episodes.
Basically, you’re giving the model way more realistic visual variety to learn from than DR alone can produce — like having a generative model serve as an “imagination engine” for your policy training.
The workshop also covered a fourth strategy — SAGE (Sim-to-Real Actuation Gap Estimation) and GapONet for directly measuring and compensating the actuation gap — but I’ll save that for a future post.
Teleoperation: Harder Than It Looks
Before evaluating any policies, we had to collect demonstrations via teleoperation — physically moving a leader arm while the robot copies your movements and the system records joint positions and camera feeds. It’s way harder than it sounds: you have to operate purely from the camera views (not look at the robot directly), keep your motions smooth and deliberate, and actually complete the task successfully. My first few attempts were… not great.
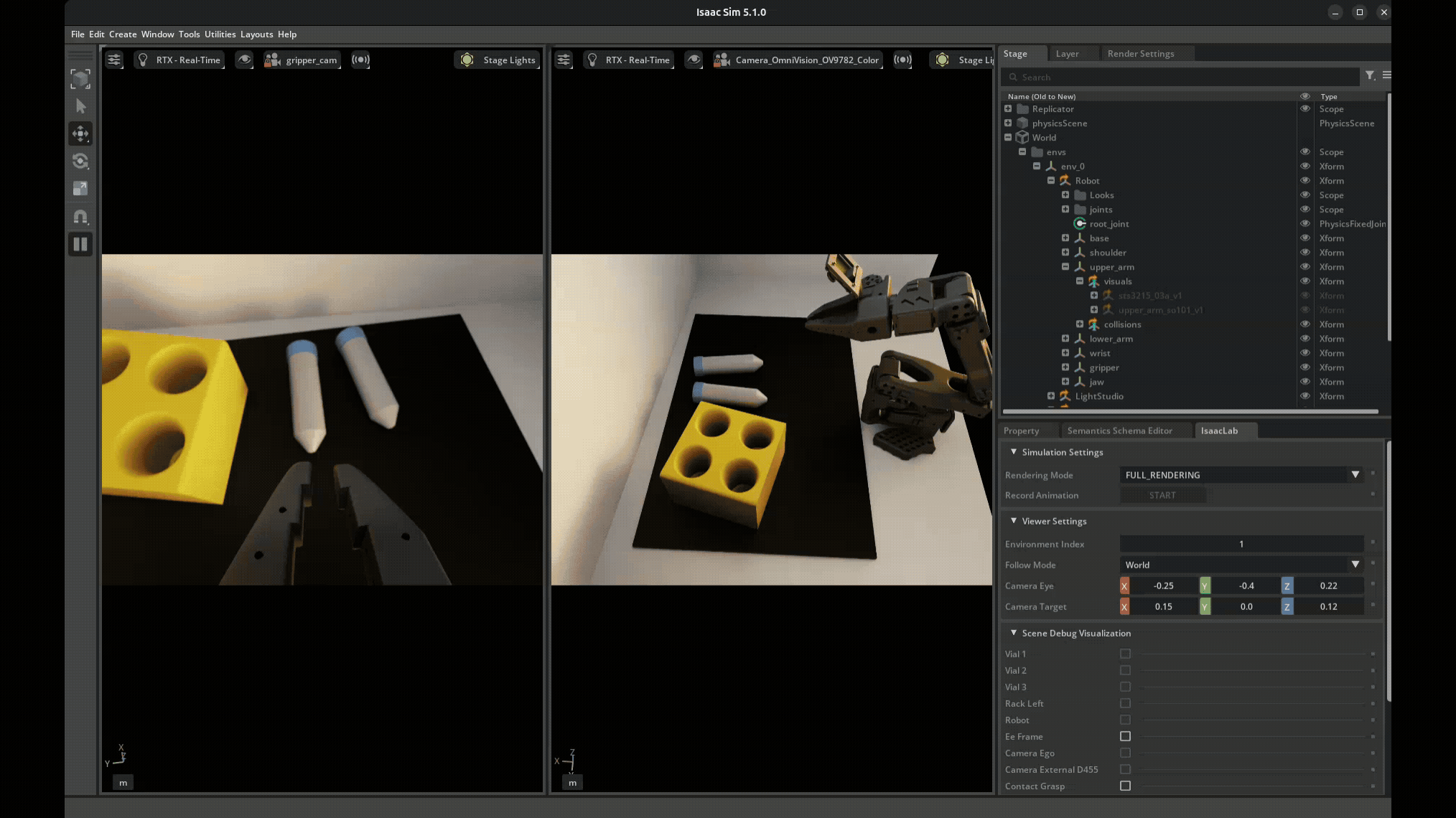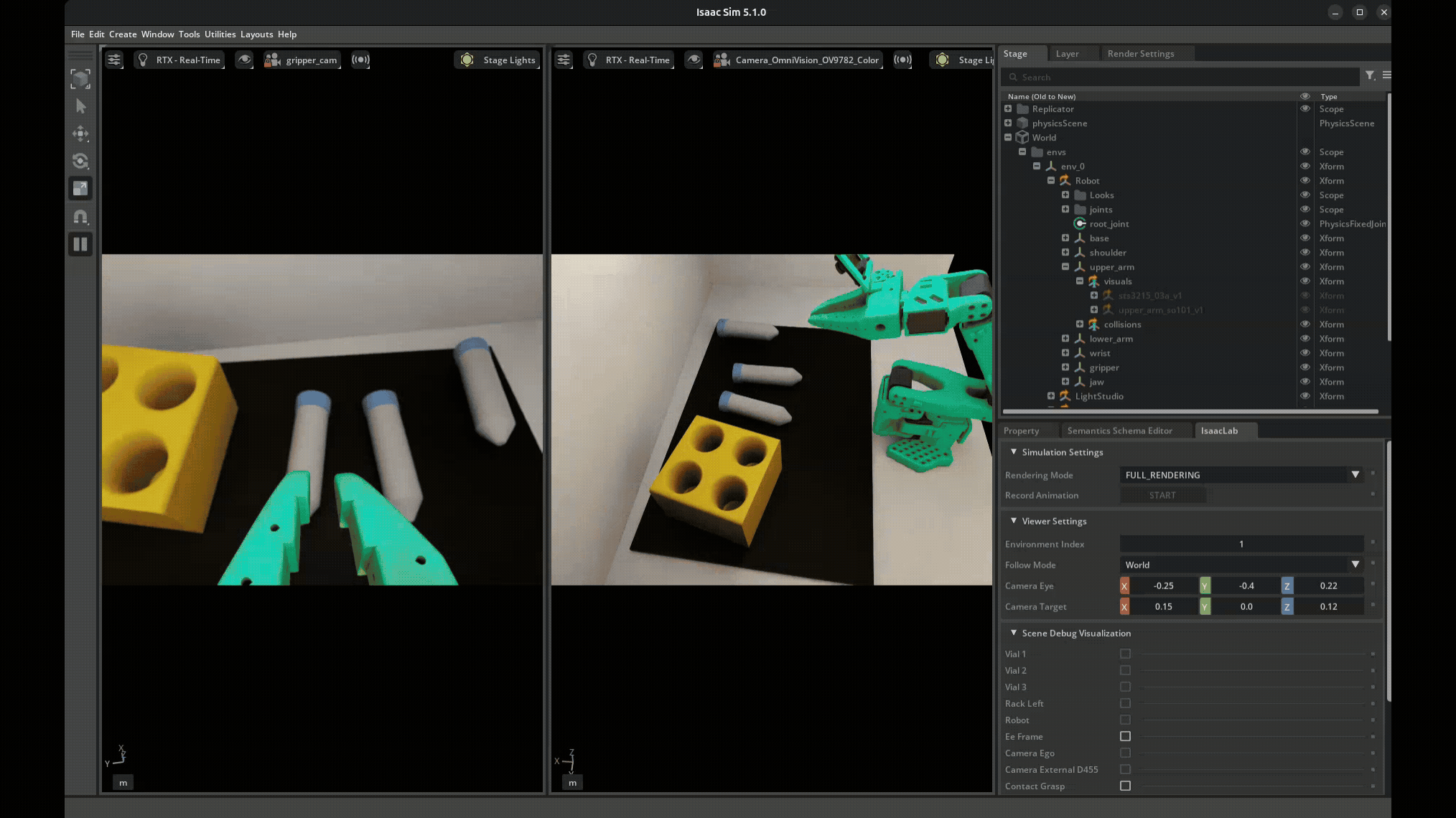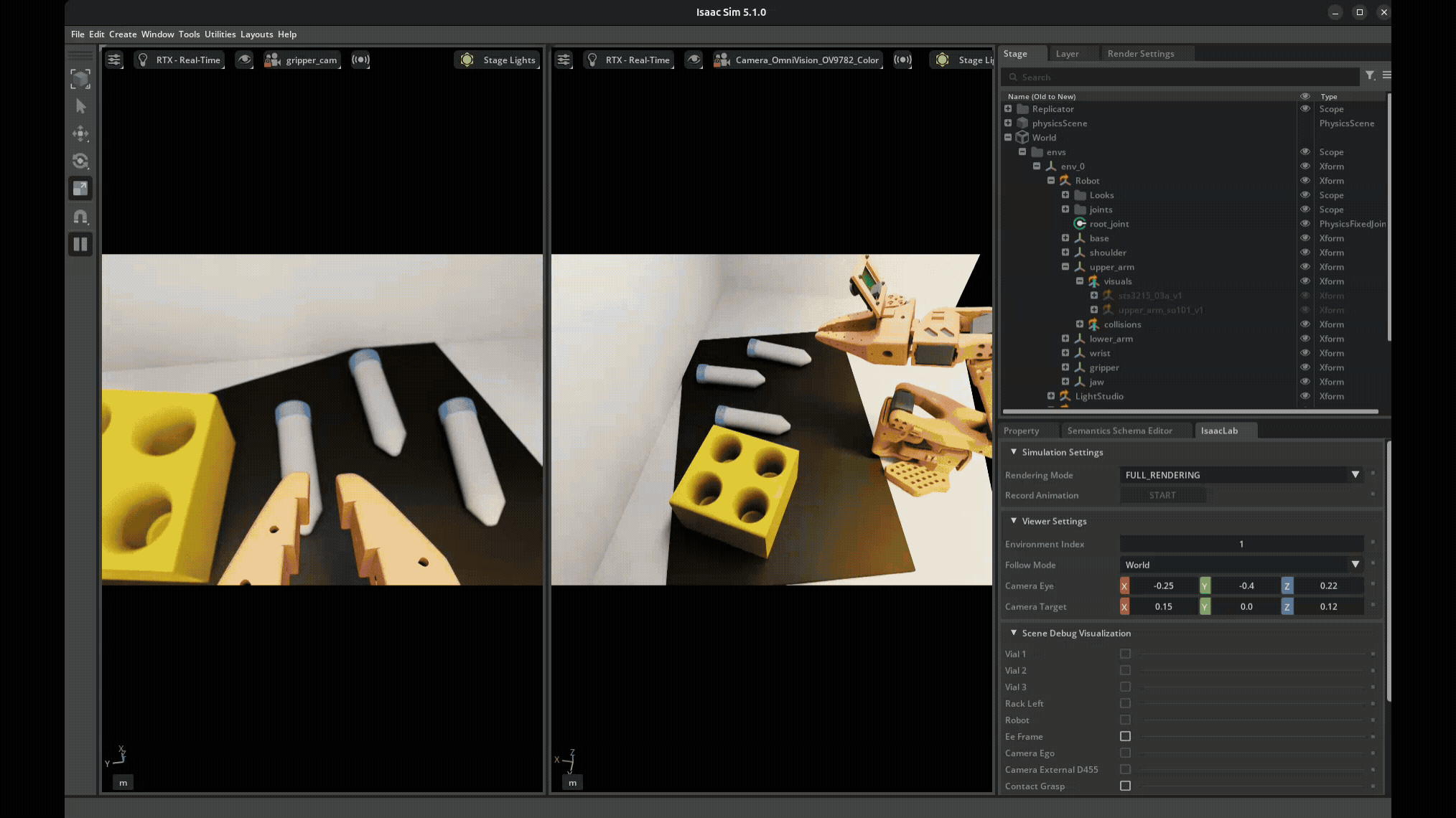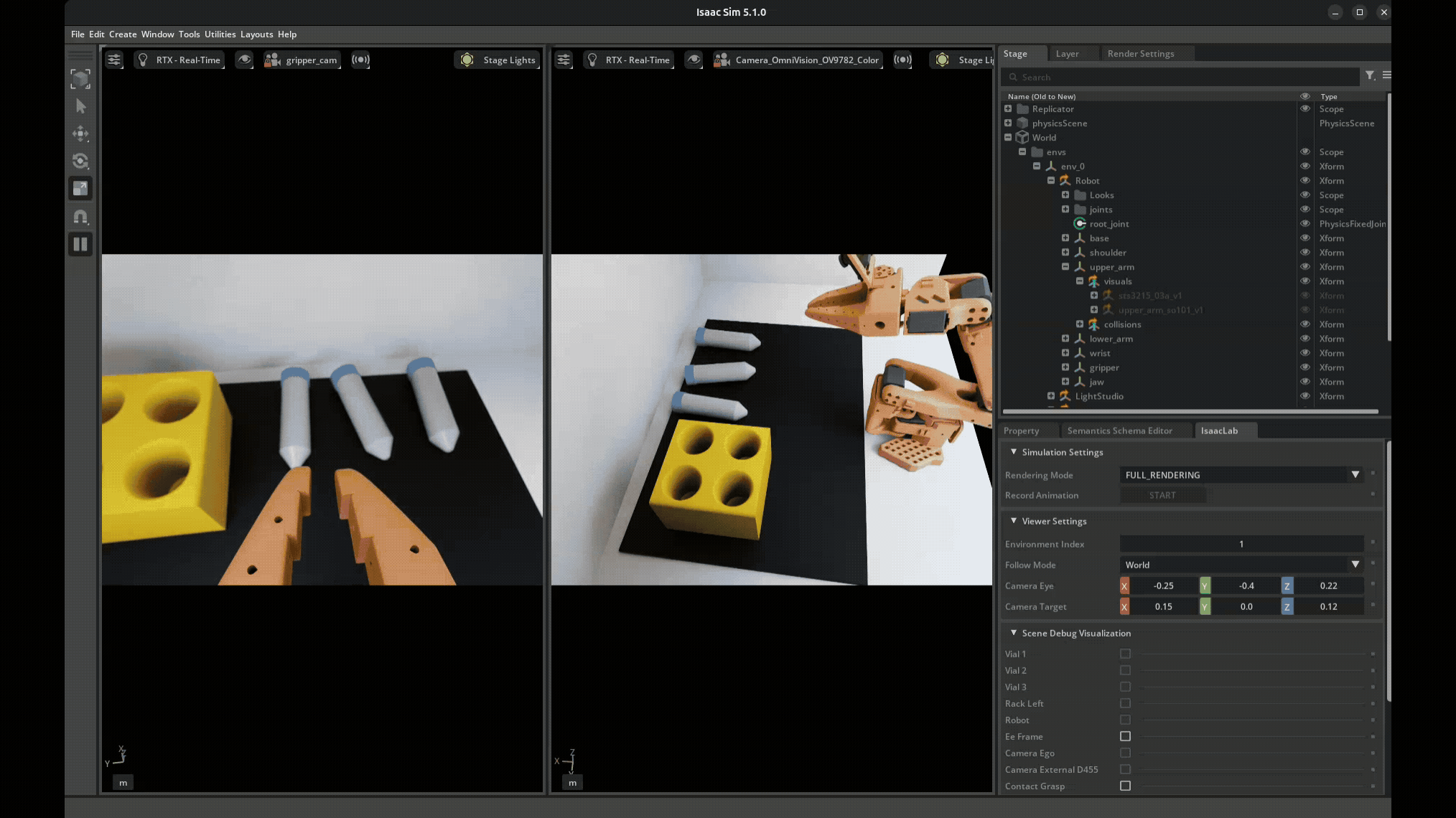
Each time you reset, the domain randomization kicks in — new lighting, new object positions, new camera offsets. So every demonstration is visually distinct, which is the whole point. We collected around 75 demonstrations in simulation this way, each one taking maybe 30-60 seconds of careful manipulation.
The quality of your demonstrations directly impacts policy performance. Jerky or sloppy teleop produces jerky policies. This is one of those things that sounds obvious in a lecture but really clicks when you see the robot reproduce your exact bad habits.
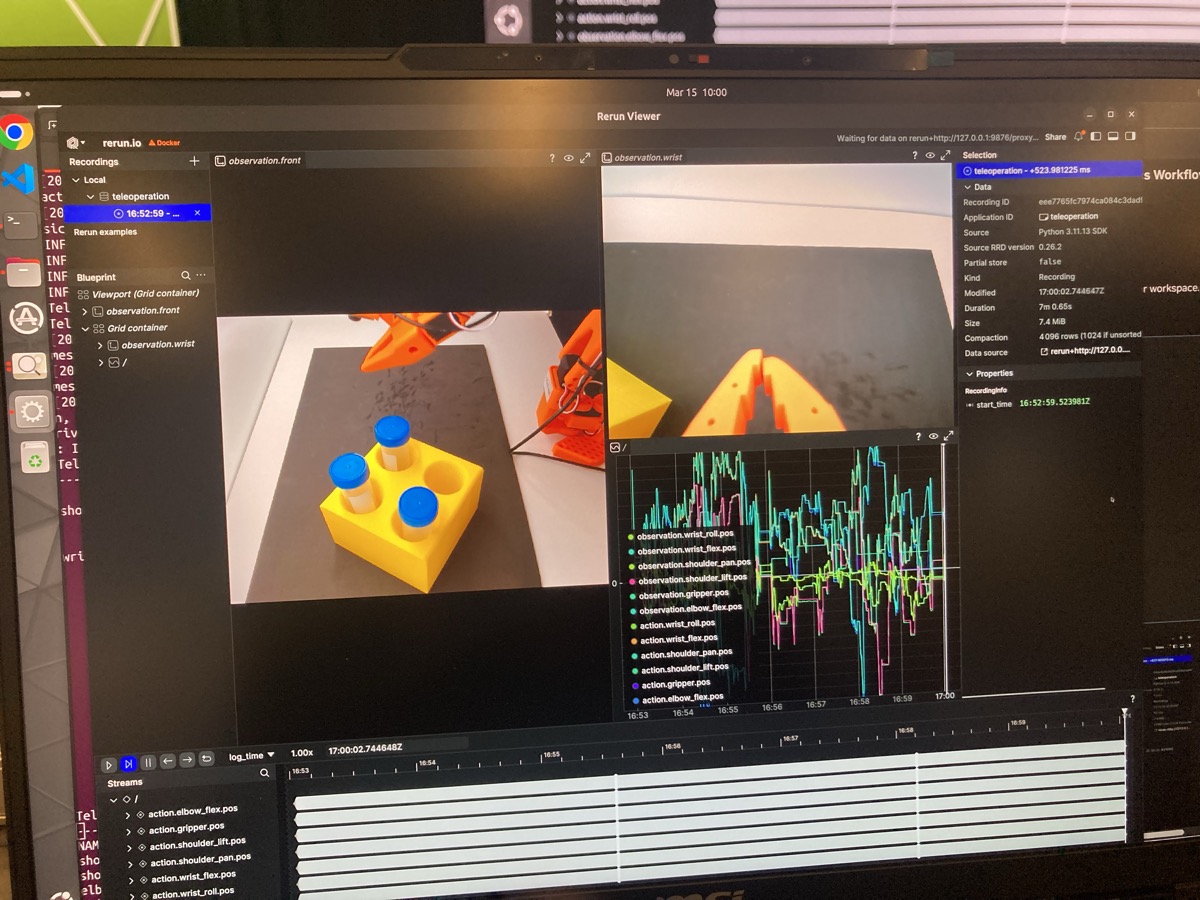
What Actually Happened on the Real Robot
Alright, enough theory. Here’s what actually happened.

Baseline (Sim-only + DR): Decent in Sim, Struggled in Reality
The baseline model achieved ~70% success in simulation, but on the real robot, the story was different. It didn’t know how to recover from boundary conditions — when the arm reached the edge of the workspace, it would get stuck rather than resetting. Gripping was unreliable. Interestingly, performance improved slightly when we hand-held the foam mat to stabilize the visual scene, which tells you how sensitive the vision pipeline is to small perturbations.
Left: a baseline success case. Right: the baseline struggling and needing lots of help.
The robot getting stuck at the workspace boundary — it doesn’t know how to recover.
Co-Trained Model: Noticeably Better
The co-trained model (sim + real data) was a clear step up. It could consistently pick up 1 of 3 vials and place it correctly. The movement was much smoother — less jerky, more deliberate. It was also less likely to get stuck at workspace boundaries.
But it had a spatial reasoning limitation that I found really interesting: it consistently dropped vials into the bottom two holes (closest to the robot base), even when those were already filled. It didn’t understand that when a hole is occupied, it should try a different one. My guess is that during teleop, most people (myself included) naturally dropped vials into the nearest holes, so the policy just learned to always target that region — a classic case of spurious correlations in behavioral cloning. It learned a positional prior (“drop near the base”) rather than the semantic goal (“find an empty hole”).
Co-trained model (Cosmos 7) — smoother movements than baseline, but still biased toward nearest holes.
Best Performer: Sim + Cosmos 70
The model trained with 75 sim episodes + 70 Cosmos-augmented episodes was the clear winner. In our setup, it could reliably get 2 out of 3 vials placed correctly with minimal human intervention. The movements were fluid and confident.
Cosmos 70 model — smoother, more confident movements.
Persistent Issue: Not Knowing When to Stop
One behavior showed up across all model iterations — the robot doesn’t know when the task is complete. After placing all vials, it keeps searching for more rather than stopping. This makes sense: behavioral cloning learns how to do the task but not when it’s done. The training data always has more vials to pick up, so the policy never learned a “finished” state.
The robot keeps searching for vials after completing the objective — observed in both the baseline (left) and co-trained (right) models.
The Fun Part: Breaking Things on Purpose
After running the standard evaluations, we got to experiment. This was honestly the most fun part of the day.
Experiment A: Changing the Language Instruction
We changed the VLA instruction from “to a yellow rack” to “to the leftmost hole of the yellow rack”.
Result: The robot’s motion became noticeably jerkier, and it still dropped the vial at the closest hole — not the leftmost one. The jerkiness is a telltale sign of out-of-distribution (OOD) inputs. The model had never seen this instruction during training, so it’s extrapolating in language-embedding space, producing less confident (and therefore less smooth) action predictions.
This really made me wish the model could output an epistemic uncertainty estimate — basically a signal saying “I don’t understand this instruction.” In Bayesian deep learning terms, epistemic uncertainty captures what the model doesn’t know due to limited training data, as opposed to aleatoric uncertainty (inherent noise in the environment). A VLA that could tell you “I’m uncertain about this instruction” would be so much more useful in deployment than one that confidently does the wrong thing.
Experiment B: Swapping the Target Object
We changed the instruction to “to a blue cup” and physically replaced the yellow rack with a blue cup.
Result: Jerky movement again, and the robot still dropped the vial at the same height and position as where the yellow rack used to be — not where the blue cup actually was. It had basically memorized “the yellow rack is here” and had no idea what to do with the blue cup.
This is a clean example of the specialist vs. generalist tradeoff in imitation learning. The model is excellent at the specific task it was trained on (vials to yellow rack), but it can’t handle novel targets. It learned where to put things, not what to put things in. In CS285 terms, behavioral cloning learns a direct mapping from observations to actions (the policy π(a|o)) — but it doesn’t learn a reward function or goal representation that would enable generalization. If the model had learned “place the vial in the target container” as an abstract goal (as in goal-conditioned RL), it might have adapted.
To make this work, you’d need additional imitation learning demonstrations with the blue cup — the model can’t reason about novel objects from language alone.
Experiment C: Turning Off the Lights
We switched off the lightbox illumination entirely.
Result: The model performed fine. This one was the most satisfying to watch because it directly validates that domain randomization worked. The lighting randomization during training (varying exposure, color temperature, HDRI maps) made the policy robust to lighting perturbations — exactly what DR is designed to do. The real-world “lights off” condition fell within the distribution the policy had already been trained on.
What I Want to Try Next
So the pattern is pretty clear at this point — behavioral cloning is great at reproducing what you showed it, but it doesn’t learn why those trajectories work. The spatial reasoning gap (always dropping in the nearest hole) and the generalization gap (can’t adapt to a blue cup) both come from the same root cause: BC mimics surface-level behavior without recovering the underlying task semantics.
CS285 discusses how reward functions encode exactly the kind of task semantics that demonstrations leave implicit. If the model had a reward signal like “place vial in an empty hole” rather than just mimicking demonstrated placements, it could learn the spatial reasoning we’re missing. But recovering that reward from demonstrations alone (the inverse RL problem) is hard — if the demonstrations are biased toward the nearest holes, IRL would likely recover that same bias.
This is why I’m most excited about exploring policy gradient methods like PPO as a next step. Instead of learning from demonstrations, you optimize directly against a reward signal. The key questions:
- How much data do you need? Policy gradient methods are notoriously sample-inefficient. But with a sim environment that supports 1000x+ parallel rollouts, this becomes tractable
- What reward function? The workshop’s sim environment already tracks subtask completion (grasp detected, release detected, rack placement detected) — these could serve directly as reward signals
- Sim-to-real for RL policies? DR and Cosmos would still be necessary to close the visual gap, but an RL-trained policy might be more robust to novel configurations because it’s optimizing a reward rather than mimicking a fixed set of demonstrations
The most promising path is probably the hybrid approach: use behavioral cloning to initialize (warm-start from demonstrations), then fine-tune with RL against a shaped reward. This is exactly the three-stage training pipeline described in the GR00T architecture — pre-training, supervised imitation, then optional RL fine-tuning. I want to actually run that pipeline end-to-end.
I also want to use SAGE to visualize the sim-to-real gap per-joint on the SO-101. The workshop introduced the pipeline — run the same motion in sim and on the real robot, then compare joint positions, velocities, and torques — but we didn’t get to run the full analysis on our own robot. Having a quantitative breakdown of where the gap is largest would make it much easier to decide whether to tune sim parameters or invest in more training data.
Another thing I want to dig into: the jerkiness problem. Multiple experiments produced jerky motion — the OOD instruction change, the blue cup swap, and even the baseline model on real hardware. Action chunking helps (predicting 16 future steps at once smooths things out), but there’s a fundamental tension: longer chunks are smoother but less reactive, shorter chunks are reactive but jerky. Real-Time Chunking (RTC) from Physical Intelligence proposes an elegant solution — instead of committing to an entire action chunk and then re-planning, RTC blends overlapping chunks in real time, giving you the smoothness of long-horizon predictions with the reactivity of short ones. This seems like exactly the right tool for the jerky-motion failures I observed, and I’d love to see how it interacts with the sim-to-real gap.
Takeaways
On the workshop itself: Easily one of the best hands-on workshops I’ve attended. The instructors were animated and engaged, the pace was well-calibrated, and having everything pre-configured — Isaac Sim, GR00T, the robot hardware, the teleoperation pipeline — meant we could focus on the science rather than debugging CUDA drivers. (I’d previously tried setting up Isaac Sim on a remote cloud instance and couldn’t get it working, so having a ready-to-go environment was a huge quality-of-life improvement.) Being able to experience the full end-to-end robotics workflow — from teleop data collection to sim training to real deployment — in a single day was genuinely special.
On sim-to-real: The gap is real, multi-dimensional, and humbling. No single strategy solves it — you need to layer domain randomization, real data co-training, synthetic augmentation (Cosmos), and actuation compensation (SAGE/GapONet). The workshop’s four-strategy framework is a clean mental model for thinking about where your transfer is failing and what to try next.
On imitation learning: Behavioral cloning gets you surprisingly far with pre-trained VLA models and ~50-100 demonstrations. But it hits a ceiling — the policy learns to mimic trajectories without understanding task semantics. For more robust behavior, you need either more diverse data, better reward signals (hello PPO), or both.
If you get a chance to attend a GTC workshop, I’d really recommend the hands-on robotics ones. And if you’ve been experimenting with sim-to-real transfer, I’d love to hear what strategies worked for you — feel free to reach out!
References
- NVIDIA Isaac GR00T Developer Guide
- LeRobot (Hugging Face)
- SAGE — Sim-to-Real Actuation Gap Estimation
- NVIDIA Cosmos World Foundation Models
- CS285: Deep Reinforcement Learning (UC Berkeley)
- Our Teleoperation Dataset on HuggingFace
- SO-101 Robot (The Robot Studio)
- Real-Time Chunking (Physical Intelligence)
- Robot Learning Tutorial (LeRobot / HuggingFace)
- Wonder Robotics: Three Things (vruga)