SafetyGuardian
Real-Time Hazard Detection for Elderly Park Walks Using Phone Camera and Cosmos-Reason2-2B
NVIDIA Cosmos Cookoff 2026Overview
SafetyGuardian: wearable AI safety for elderly park walks
SafetyGuardian is a wearable AI safety system that uses a phone camera to detect environmental hazards in real time as elderly users walk through parks. Training data was curated from synthetic videos generated with Cosmos-Predict2.5-2B, and the Cosmos-Reason2-2B model was supervised fine-tuned (SFT) to produce concise, structured hazard assessments. At inference time, frames are streamed to the fine-tuned model served via vLLM, and responses are converted to natural voice warnings through ElevenLabs TTS — all within ~1.07 seconds end-to-end.
The model outputs a structured assessment in this format:
HAZARD: <type> | SEVERITY: <level> | ACTION: <instruction>Examples:
HAZARD: clear | SEVERITY: none | ACTION: proceed safely
HAZARD: ice | SEVERITY: high | ACTION: slow down
HAZARD: vehicle | SEVERITY: critical | ACTION: stop immediatelyDemo
SafetyGuardian demo walkthrough
Problem & Motivation
Falls are a leading cause of injury and death among adults aged 65 and older. Each year, millions of older adults experience falls — many of which occur during routine outdoor activities like walking in parks, crossing streets, or navigating uneven terrain. Most existing solutions are reactive, detecting falls after they happen. SafetyGuardian takes a fundamentally different approach.
Fall Hazards
- Uneven surfaces
- Tree roots
- Cracked pavement
- Ice patches
- Wet leaves
- Puddles
- Stairs without railings
Collision Risks
- Cyclists
- Skateboarders
- Dogs on/off leash
- Joggers
- Children running
- Vehicles near crossings
Why proactive early-warning beats reactive fall detection: SafetyGuardian warns before an incident occurs, giving the user time to slow down, change direction, or stop — rather than detecting a fall after it has already happened.
Beyond elderly care: The same voice-based hazard warning system is directly applicable to blind and visually impaired users, who face many of the same environmental hazards — uneven surfaces, approaching vehicles, obstacles — but lack the visual cues to detect them. SafetyGuardian's audio-first design makes it a natural fit for accessibility applications.
System Architecture

End-to-end system architecture
Cloud vs On-Device Comparison
Running the 4GB+ Cosmos-Reason2-2B model on-device would take 56+ seconds per frame — far too slow for real-time safety warnings — so we chose cloud inference to achieve sub-second latency at the cost of requiring network connectivity.
| Metric | Cloud (L40S) | On-Device (iPhone) |
|---|---|---|
| Inference time | 0.65s | 56s+ |
| Compute | 360 TFLOPS | ~6 TOPS |
| VRAM/Memory | 48 GB | 4-8 GB |
| Battery impact | Minimal | Severe |
| Scalability | 50-100 users | Single device |
Latency Breakdown
Total: ~1.07s — well within the 20-second processing interval
iPhone App
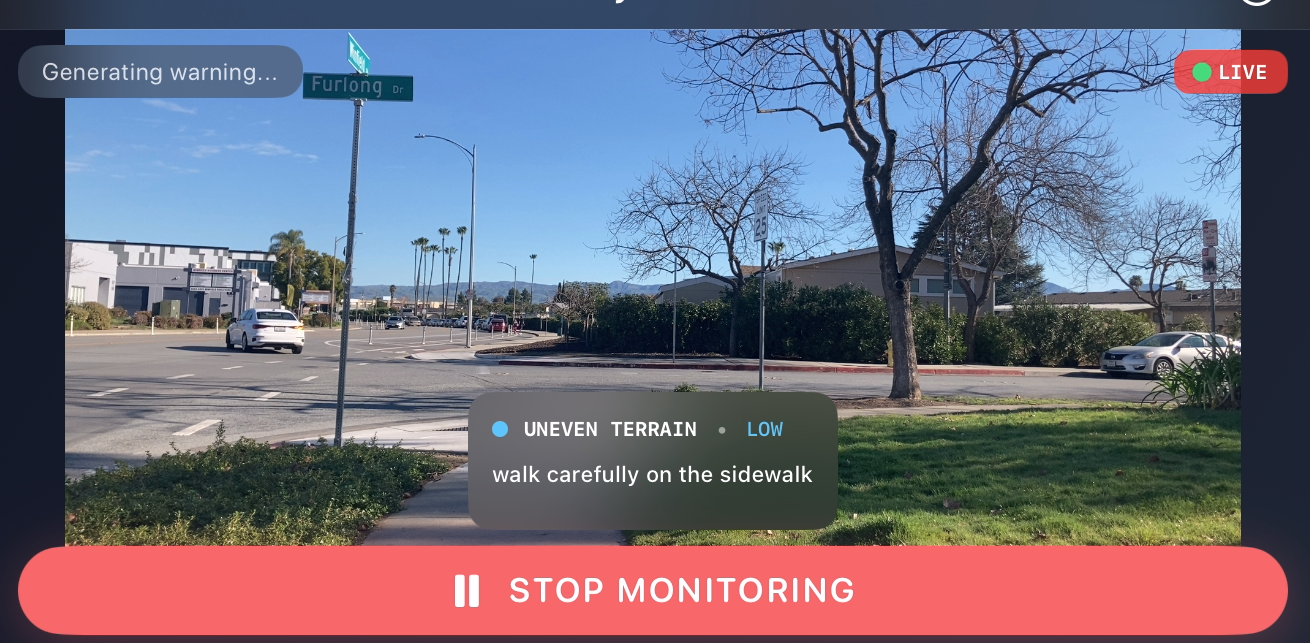
Main screen with live camera feed
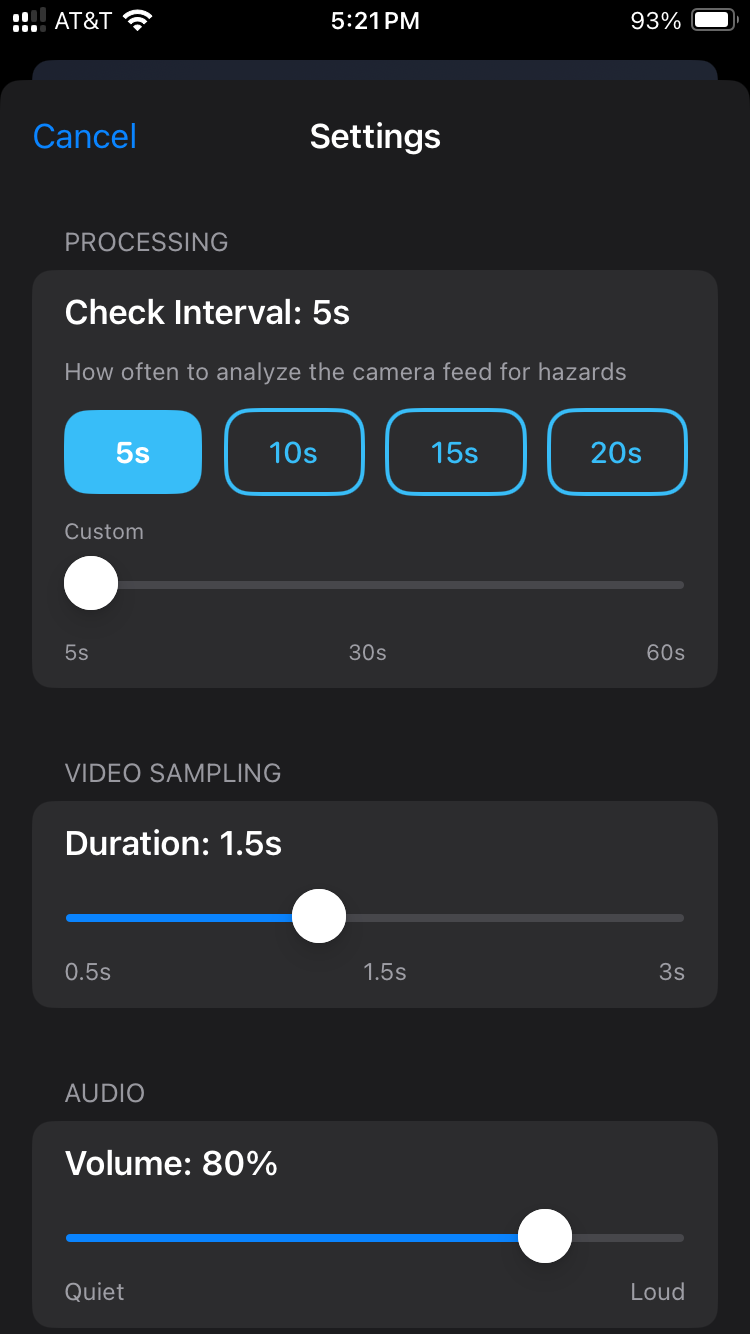
Settings and configuration
Features
- Continuous camera capture at 30 FPS
- Configurable processing intervals (5-60 seconds, default 20s)
- External wearable camera support via USB-C/Lightning
- Real-time hazard detection via cloud API
- Natural voice warnings using ElevenLabs Rachel voice
- Robust error handling with exponential backoff (3x inference, 2x TTS)
- Background audio support
- Settings UI for customization
Data Pipeline

Data curation pipeline from raw video to training samples
Video Generation
Training videos were generated using NVIDIA Cosmos-Predict2.5-2B, a diffusion transformer for future-state prediction. Each video simulates a first-person perspective across outdoor locations — parks, paths, intersections, bridges, and riversides. 106 unique scenarios were generated across 11 hazard categories: clear, pedestrian, wet surface, vehicle, obstacle, ice, puddle, narrow path, animal, uneven terrain, and flood.
Frame Extraction & Image Optimization
5 representative frames were extracted per video at regular intervals
(frame_01.jpg through frame_05.jpg), capturing
the progression from initial approach to fully visible hazard. Frames were then resized from
1280×720 (~890 tokens/sample) to 400×400 with max_pixels=160000
(~300 tokens/sample) — a 3× improvement in token efficiency, raising the
target token ratio from 1.8% to 5.6%.
Automatic Review
All 530 frames were first analyzed by the base Cosmos-Reason2-2B model in a
zero-shot setting. The model's predictions were saved as model_analysis.json for
each video, providing baseline hazard/severity/action labels before any human review. This
automated pass established initial annotations and allowed human reviewers to focus on
correcting errors rather than labeling from scratch.
Human Feedback
Human reviewers rated each video on a 1-5 quality scale, corrected mislabeled hazard types and severity levels, and flagged unrealistic or unusable scenes. Approximately 35 low-quality videos (ratings 1-2) were removed during this stage.
Quality Filtering
After human review, additional quality filtering removed remaining issues:
| Reason | Examples | Impact |
|---|---|---|
| Camera shifts | Non-continuous footage | Excluded |
| Wrong perspective | Hazard not visible from FPV angle | Excluded |
| Misleading early frames | Hazard not yet visible in frames 1-2 | 25 samples removed |
Additionally, 26 samples were enriched using reviewer notes to resolve unknown or ambiguous labels, and early frames were removed from 13 dynamic hazard videos where the hazard was not yet visible — eliminating contradictory training signals. Final dataset: 264 curated samples from 66 unique video scenarios.
Hazard Samples

Clear

Ice

Puddle

Vehicle

Pedestrian

Wet Surface

Obstacle
Fine-Tuning
Base Model
Cosmos-Reason2-2B (Qwen3-VL architecture)
Method
LoRA fine-tuning via TRL SFTTrainer
Hardware
Single NVIDIA H100 80GB GPU
Dataset
237 train / 27 validation (90/10 split)
LoRA Configuration
LoraConfig(
r=64,
lora_alpha=64,
lora_dropout=0,
target_modules=["down_proj", "o_proj", "k_proj", "q_proj",
"gate_proj", "up_proj", "v_proj"],
)Hyperparameter Search
20 trials were run across two Optuna studies, each training for 5 epochs with linear LR schedule and 10% warmup. OOM configurations were automatically pruned.
| Parameter | Search Range | Best Value |
|---|---|---|
| Learning rate | 1e-5 to 5e-4 (log scale) | 4.4e-04 |
| LR scheduler | Linear with 10% warmup | Linear |
| Optimizer | AdamW 8-bit | adamw_8bit |
| Batch size | 8, 16, 32 | 16 |
| Gradient accumulation | 1, 2, 4 | 2 |
| LoRA rank | 32, 64, 128 | 64 |

Optuna hyperparameter search — 20 trials (best: lr=4.4e-04, bs=16, ga=2, rank=64)
Training Runs
The best configuration was retrained for 20 epochs (160 steps) with the 3 best checkpoints saved based on eval loss. Generation samples were logged to Weights & Biases every 2 epochs on 8 validation samples. The charts below show all runs across both Optuna studies and the final training run.

train/loss — all runs converge rapidly within the first ~50 steps

train/mean_token_accuracy — plateau at ~0.52 after convergence

eval/mean_token_accuracy — consistent validation performance across top runs
Results
Hazard Distribution
Severity Distribution
Inference Comparison: Pre-training vs Epoch 8
8 validation samples were tracked throughout training. The table below compares the base model's zero-shot output against the fine-tuned model at epoch 8.

HAZARD: ice | SEVERITY: medium | ACTION: stay center
HAZARD: ice_on_ground | SEVERITY: high | ACTION: Avoid icy patches; walk cautiously.
HAZARD: ice | SEVERITY: medium | ACTION: slow down

HAZARD: animal | SEVERITY: high | ACTION: stop
HAZARD: uneven terrain | SEVERITY: medium | ACTION: avoid uneven patches while walking
HAZARD: animal | SEVERITY: medium | ACTION: stop

HAZARD: clear | SEVERITY: none | ACTION: proceed safely
HAZARD: uneven terrain | SEVERITY: high | ACTION: Avoid walking on the uneven path; stay on the paved surface.
HAZARD: clear | SEVERITY: none | ACTION: proceed safely

HAZARD: clear | SEVERITY: none | ACTION: stay alert, proceed slowly
HAZARD: cracked pavement | SEVERITY: critical | ACTION: Repair cracked asphalt to prevent slips and falls.
HAZARD: clear | SEVERITY: none | ACTION: proceed safely

HAZARD: wet surface | SEVERITY: medium | ACTION: caution
HAZARD: cracked pavement | SEVERITY: high | ACTION: Repair cracked asphalt to prevent slips and falls.
HAZARD: clear | SEVERITY: none | ACTION: proceed safely

HAZARD: puddle | SEVERITY: high | ACTION: avoid area
HAZARD: puddle | SEVERITY: high | ACTION: avoid puddle to prevent slipping
HAZARD: puddle | SEVERITY: high | ACTION: detour
Key observations: Pre-training outputs are verbose, use inconsistent formatting, frequently misidentify hazard types (e.g., "cracked pavement" for clear paths), and inflate severity levels. After fine-tuning, outputs are concise, correctly structured, and substantially more accurate in both hazard identification and severity assessment.
Cost Analysis
Per-user monthly cost breakdown assuming 20-second processing intervals, 24/7 operation:
| Component | Monthly Cost |
|---|---|
| Cosmos inference (130k requests) | ~$13 |
| ElevenLabs TTS (4.9M chars) | ~$148 |
| GPU server (shared, 50 users) | ~$18-36 |
| Total per user (shared) | $31-36 |
| Total per user (dedicated) | $179-197 |
Key insight: Shared GPU infrastructure reduces per-user cost by 83%, making the system economically viable for deployment.
Next Steps
Further Directions
- Edge Deployment — Explore on-device inference using quantized models (INT4/INT8) on next-generation mobile chips to eliminate cloud dependency and enable offline operation.
- Multi-Modal Sensing — Combine camera input with IMU/accelerometer data to detect gait instability and predict falls before they happen.
- Cost Optimization — Reduce TTS costs (currently 80% of per-user expense) by evaluating open-source alternatives. Batch inference with vLLM's continuous batching could further reduce GPU cost per request.
Longer-term goals include a larger-scale user study with elderly participants, integration with smart city infrastructure (traffic signal data, construction zone APIs), and expanding the hazard taxonomy to cover indoor environments such as hospitals and care facilities.
Acknowledgments
Thanks to NVIDIA for organizing the Cosmos Cookoff 2026 and providing access to the Cosmos model family.
Thanks to Nebius for GPU infrastructure (L40S and H100 instances).
References
- NVIDIA Cosmos-Reason2-2B — Physical AI reasoning model
- vLLM — High-throughput LLM serving engine
- ElevenLabs — Text-to-speech API (Turbo v2.5)
- LoRA — Low-Rank Adaptation for efficient fine-tuning
- Optuna — Hyperparameter optimization framework