Distilling a 6B Image Model with LADD: Architecture, Experiments & Hard Lessons
April 5, 2026
Target audience: ML engineers familiar with diffusion models who want to understand how adversarial distillation works in practice — including the parts that break.
This is Part 2 of our series on distilling Z-Image, a 6.15B parameter text-to-image model. Part 1 covered data curation — how we assembled 500K diverse prompts from 9 sources. This post covers the training framework: the architecture, the loss function, hyperparameter tuning, scaling to 8 GPUs with FSDP, and the blunders that taught us the most.
Table of Contents
- Overview
- The LADD Architecture
- The Discriminator Design
- Loss Function & Training Loop
- Hyperparameter Experiments
- Results: 4 Steps vs 50 Steps
- Scaling Up: The FSDP Journey
- The Hard Lessons: Blunders & Principles
- Summary & Next Steps
- Key References
1. Overview
The goal is simple to state: take a 50-step diffusion model and make it generate images in 4 steps, with minimal quality loss. The method is LADD — Latent Adversarial Diffusion Distillation (Sauer et al., 2024).
Unlike traditional knowledge distillation that minimizes MSE between teacher and student outputs, LADD uses adversarial training — a GAN (Generative Adversarial Network) — in the teacher’s latent feature space. A lightweight discriminator learns to distinguish teacher features from student features, and the student learns to fool it. No pixel-space losses, no perceptual networks, no FID-optimizing tricks — just a GAN operating on frozen teacher representations.
The setup involves three models cooperating in a delicate balance:
| Component | Parameters | Role | Trainable |
|---|---|---|---|
| Student (S3-DiT) | 6.15B | Denoises in fewer steps | Yes |
| Teacher (S3-DiT) | 6.15B | Provides feature representations | No (frozen) |
| Discriminator (Conv heads) | 14M | Multi-scale adversarial feedback | Yes |
| Text Encoder (Qwen3) | ~3B | Encodes prompts | No (frozen) |
| VAE (AutoencoderKL) | ~0.5B | Latent ↔ pixel conversion | No (frozen) |
The student is initialized as an exact copy of the teacher. Training teaches it to skip steps — to produce in 4 steps what the teacher produces in 50.
2. The LADD Architecture

The architecture has three key ideas that separate it from simpler distillation approaches.
Idea 1: The student predicts velocity, not noise
Z-Image uses flow matching (Lipman et al., 2023) — a framework where, unlike noise-prediction diffusion (DDPM), the forward process interpolates linearly between data and noise, and the model predicts the velocity of that interpolation:
\[x_t = (1 - t) \cdot x_0 + t \cdot \varepsilon\]- $x_0$: clean latent (teacher-generated with CFG=5, 50 steps)
- $\varepsilon$: Gaussian noise
- $t$: timestep in $[0, 1]$ — higher means noisier
The student predicts a velocity $v_\theta$ and we recover the denoised latent:
\[\hat{x}_0 = x_t - t \cdot v_\theta(x_t, t, c)\]- $v_\theta$: student’s velocity prediction
- $c$: text conditioning from Qwen3
This is implemented in train_ladd.py:824:
# Convert velocity to denoised latent: x̂_0 = x_t - t * v
student_pred = x_t - t_bc * student_velocity
Idea 2: Re-noising creates a shared comparison space
The student’s denoised prediction $\hat{x}_0$ and the teacher’s clean latent $x_0$ can’t be compared directly by the discriminator — they might be at different quality levels for trivial reasons (the student just started training). Instead, both are re-noised to a shared noise level $\hat{t}$, sampled from a logit-normal distribution — a distribution that applies a sigmoid to a Gaussian sample, concentrating values in $(0, 1)$ away from the extremes:
\[\text{fake: } (1 - \hat{t}) \cdot \hat{x}_0 + \hat{t} \cdot \varepsilon_1\] \[\text{real: } (1 - \hat{t}) \cdot x_0 + \hat{t} \cdot \varepsilon_2\]This ensures the discriminator sees a smooth mix of noise levels rather than specializing on one scale.
From ladd_utils.py:59-76:
def logit_normal_sample(batch_size, m=1.0, s=1.0, device="cpu", generator=None):
"""Sample from logit-normal: u ~ Normal(m, s²), t = sigmoid(u)."""
u = torch.normal(mean=m, std=s, size=(batch_size,), generator=generator, device=device)
t = torch.sigmoid(u)
t = t.clamp(0.001, 0.999)
return t
Idea 3: Gradients flow through the frozen teacher
This is the subtlest part. The teacher’s weights are frozen (requires_grad_(False)), but on the fake path, the computation graph is kept alive — no torch.no_grad(). This means gradients flow backward through the teacher’s operations to reach the student:
student → x̂₀ → re-noise → teacher(forward, no_grad on weights) → disc → g_loss
↑ gradients flow through here
The real path uses torch.no_grad() because no gradient is needed — it’s just providing a reference.
From train_ladd.py:914-920:
# Teacher forward WITH gradient graph (frozen weights, live graph)
_, fake_extras_grad = teacher(
fake_input_grad,
t_hat,
prompt_embeds,
return_hidden_states=True,
)
3. The Discriminator Design

The discriminator is not a full model — it’s 6 independent lightweight heads, each attached to a different layer of the teacher transformer. This multi-scale design is what makes LADD work with only 14M parameters (0.2% of the student).
Why multiple layers?
Each teacher transformer block captures different abstractions:
| Layers | What they capture | Why it matters |
|---|---|---|
| 5, 10 | Texture, local patterns | Catches blurriness, color artifacts |
| 15, 20 | Object composition, spatial relationships | Catches structural errors |
| 25, 29 | Semantics, prompt alignment | Catches meaning drift |
If the discriminator only watched one layer, the student could learn to fool that specific abstraction level while degrading at others. Six layers make gaming the system much harder.
Head architecture
Each head is a small convolutional network with FiLM conditioning (Feature-wise Linear Modulation) from the timestep and text embedding. FiLM works by learning a per-channel scale and shift from the conditioning signal, so the discriminator can adjust which features matter depending on the noise level and prompt:
From ladd_discriminator.py:67-72:
cond = torch.cat([t_embed, text_embed], dim=-1) # conditioning signal
film_params = self.cond_mlp(cond) # MLP predicts scale+shift
scale, shift = film_params.chunk(2, dim=-1) # split in half along last dim
h = h * (1.0 + scale) + shift # modulate features
The MLP outputs a vector of size hidden_dim * 2 (512), and .chunk(2, dim=-1) splits it into two halves of 256 each — one for scale, one for shift. Each feature channel gets its own modulation: a scale near 0 suppresses that channel, a large scale amplifies it.
The full head architecture from ladd_discriminator.py:18-85:
class LADDDiscriminatorHead(nn.Module):
def __init__(self, feature_dim=3840, hidden_dim=256, cond_dim=256):
super().__init__()
# FiLM conditioning: timestep + text → scale, shift
self.cond_mlp = nn.Sequential(
nn.Linear(cond_dim * 2, hidden_dim),
nn.SiLU(),
nn.Linear(hidden_dim, hidden_dim * 2), # scale + shift
)
self.proj = nn.Linear(feature_dim, hidden_dim)
# 2D conv layers (applied after reshaping tokens to spatial layout)
self.conv1 = nn.Conv2d(hidden_dim, hidden_dim, 3, padding=1)
self.gn1 = nn.GroupNorm(32, hidden_dim)
self.conv2 = nn.Conv2d(hidden_dim, hidden_dim // 2, 3, padding=1)
self.gn2 = nn.GroupNorm(16, hidden_dim // 2)
self.conv_out = nn.Conv2d(hidden_dim // 2, 1, 1)
The pipeline per head: Linear projection (3840→256) → FiLM modulation (scale + shift from timestep and text) → reshape to 2D spatial → two conv blocks with GroupNorm → 1×1 conv → global mean pool → scalar logit.
All 6 head logits are summed into total_logit for the final real/fake decision:
for layer_idx in self.layer_indices:
head_logits = self.heads[str(layer_idx)](img_feats, spatial_size, t_embed, text_embed)
total_logit = total_logit + head_logits
4. Loss Function & Training Loop

The hinge loss
LADD uses the hinge loss variant of adversarial training — the same loss used in spectral normalization GANs. It has a nice property: the discriminator loss saturates once it’s confident, preventing it from becoming arbitrarily strong.
From ladd_discriminator.py:202-216:
@staticmethod
def compute_loss(real_logits, fake_logits):
"""Hinge loss for GAN training."""
d_loss = torch.mean(F.relu(1.0 - real_logits)) + torch.mean(F.relu(1.0 + fake_logits))
g_loss = -torch.mean(fake_logits)
return d_loss, g_loss
Discriminator loss pushes real logits above +1 and fake logits below -1. Once confident, the ReLU clips to zero — no further gradient signal. This prevents the discriminator from running away.
Generator (student) loss is simply $-\mathbb{E}[\text{fake logits}]$ — maximize the discriminator’s score on student outputs.
The asymmetric update schedule
The discriminator and student don’t update at the same frequency. The discriminator updates every step, while the student updates only every $N$ steps (gen_update_interval):
From train_ladd.py:802, 887-944:
is_gen_step = (global_step % args.gen_update_interval == 0)
# Discriminator: always update
accelerator.backward(d_loss)
disc_optimizer.step()
# Student: update every N steps
if is_gen_step:
accelerator.backward(g_loss_update)
student_optimizer.step()
Why? The discriminator needs to stay ahead of the student to provide useful gradient signal. If both update every step, they oscillate. The discriminator uses a 10× higher learning rate (5e-5 vs 5e-6) for the same reason.
Timestep curriculum
The student sees a mix of denoising difficulties, with a curriculum that shifts from easy to hard:
From train_ladd.py:408-440:
student_timesteps = [1.0, 0.75, 0.5, 0.25]
if global_step < warmup_steps:
# Warmup: only easy tasks (shown for n=4; source computes dynamically)
probs = [0.0, 0.0, 0.5, 0.5]
else:
# Main phase: heavily favor t=1.0 (full denoising — the hard case)
probs = [0.7, 0.1, 0.1, 0.1]
At $t = 1.0$, the student starts from pure noise — this is the hardest case and what matters most for few-step inference. At $t = 0.25$, it starts from a mostly-clean input. The curriculum warms up on easy cases before emphasizing the hard one.
5. Hyperparameter Experiments
The autoresearch setup
For hyperparameter tuning, we took inspiration from Andrej Karpathy’s autoresearch concept — have an AI agent run experiments autonomously overnight. We built a lightweight framework around this idea:
research/experiment.py— the only file the agent modifies. Hyperparameters are constants at the top; the script generates a bash command, trains, evaluates, and logs to W&B.research/program.md— agent instructions: read prior results, propose the next experiment, modifyexperiment.py, run it, record the result, repeat.research/results.tsv— experiment log (commit hash, KID, VRAM, status, description).
Each experiment ran 500 steps on a single A100 80GB (the debug split: 98 prompts, 512px). The agent ran autonomously for ~8 hours overnight, completing 21 experiments across two rounds.
What we tuned (and in what order)
LADD has several hyperparameters that interact in non-obvious ways. Here’s what each one controls:
| Hyperparameter | What it controls | Default | Why it matters |
|---|---|---|---|
student_lr |
Student optimizer learning rate | 5e-6 | Too high → divergence. Too low → slow learning. |
disc_lr |
Discriminator learning rate | 5e-5 | Must stay ahead of student (typically 10× higher). |
gen_update_interval (GI) |
Discriminator steps per student update | 5 | Controls D/G balance — the most sensitive knob. |
renoise_m |
Logit-normal mean for re-noising $\hat{t}$ | 1.0 | Controls what noise level the discriminator mostly sees. Higher → more noise → harder to distinguish. |
renoise_s |
Logit-normal std for re-noising $\hat{t}$ | 1.0 | Controls spread of noise levels. Wider → more diversity in discriminator feedback. |
disc_layer_indices |
Which teacher layers get discriminator heads | [5,10,15,20,25,29] | Determines which abstraction levels are supervised. |
disc_hidden_dim |
Hidden dimension per discriminator head | 256 | Controls head capacity — too large → overfitting, too small → underfitting. |
We tuned them in this order, each time fixing the best value and moving on:
- Learning rates (student_lr, disc_lr) — establish stable training dynamics first
- Generator update interval (GI) — the D/G balance knob with the most impact
- Noise schedule (renoise_m, renoise_s) — controls discriminator’s operating point
- Discriminator architecture (layer_indices, hidden_dim) — structural choices, tuned last
Round 1: Pre-fix sweep (broken pipeline)
These results used KID (Kernel Inception Distance) — an unbiased metric preferred over FID for small sample sizes. Lower is better.
Noise schedule exploration — tuning the logit-normal distribution parameters for re-noising:
renoise_m |
renoise_s |
KID | vs baseline |
|---|---|---|---|
| 1.0 (default) | 1.0 | 0.00804 | — |
| 0.0 | 1.0 | 0.00551 | -31% |
| 0.5 | 1.0 | 0.00461 | -43% |
| -0.5 | 1.0 | 0.00508 | -37% |
| 0.5 | 0.5 | 0.00564 | -30% |
| 0.5 | 1.5 | 0.00559 | -30% |
The default $m = 1.0$ was too high — sigmoid(1.0) ≈ 0.73, meaning the discriminator mostly saw high-noise samples where real and fake are hard to distinguish. $m = 0.5$ (sigmoid(0.5) ≈ 0.62) shifted the distribution toward moderate noise levels where the discriminator gets more useful signal.
Generator update interval — how many discriminator steps per student update:
| GI | KID | vs baseline |
|---|---|---|
| 2 | 0.01102 | +37% (worse) |
| 3 | 0.00804 | baseline |
| 4 | 0.00241 | -70% |
| 6 | 0.00202 | -75% |
| 8 | 0.00087 | -89% |
| 10 | 0.01290 | +60% (worse) |
GI=8 was a dramatic win — 89% better than baseline. But this turned out to be an artifact of the broken pipeline (see Section 8).
Discriminator architecture — we also tested head configurations:
| Config | KID | Notes |
|---|---|---|
| 6 layers [5,10,15,20,25,29], dim=256 | 0.000869 | best |
| 3 layers [10,20,29] | 0.001469 | 69% worse |
| 8 layers [3,7,11,15,19,23,27,29] | 0.001513 | 74% worse |
| dim=128 | 0.001184 | 36% worse |
| dim=512 | 0.006385 | 635% worse |
The original 6-layer, 256-dim config was already optimal. More layers added noise without new signal; larger hidden dims made the heads harder to train.
Full results tracked in research/results.tsv.
Round 2: Post-fix sweep (corrected pipeline)
After fixing 5 critical bugs, we re-ran the sweep. The results shifted significantly:
| Experiment | Config change | KID | vs baseline |
|---|---|---|---|
| baseline | slr=5e-6, dlr=5e-5, GI=8 | 0.0637 | — |
| exp1 | dlr=1e-5 (lower disc LR) | 0.0624 | -2% |
| exp2 | GI=3 (was 8) | 0.0589 | -7.5% |
| exp3 | slr=2e-5 (higher student LR) | 0.0792 | +24% (worse) |
| exp4 | GI=3 + dlr=1e-5 | 0.0616 | -3.3% |
The optimal GI flipped from 8 to 3 after fixing the pipeline. Why? In the broken pipeline, “real” samples were just noise-mixed-with-noise — trivially easy for the discriminator. It needed many steps to avoid overwhelming the student. With proper teacher latents as real samples, the discrimination task became genuinely hard, and the student needed more frequent updates to keep up.
Current best configuration
STUDENT_LR = 5e-6 # Conservative — adversarial training is fragile
DISC_LR = 5e-5 # 10x student LR (disc needs to lead)
GEN_UPDATE_INTERVAL = 3 # Update student every 3 disc steps
RENOISE_M = 0.5 # LogitNormal mean (moderate noise bias)
RENOISE_S = 1.0 # LogitNormal std (wide spread)
DISC_HIDDEN_DIM = 256 # Per-head projection dimension
DISC_LAYER_INDICES = [5, 10, 15, 20, 25, 29] # 6 of 30 teacher layers
6. Results: 4 Steps vs 50 Steps
Student vs Teacher: visual comparison
Here’s what the student produces at 4 steps compared to the teacher at 50 steps (CFG=5). These images are pulled directly from our W&B eval runs.
Prompt: “The image captures a dynamic scene at a bullfighting arena…“
| Teacher (50 steps, CFG=5) | Student (4 steps, 500 train steps) | Student (4 steps, 2000 train steps) |
|---|---|---|
 |
 |
 |
Prompt: “cyberpunk birthday party with robots, androids and flamenco guitarist watching mars sunset…“
| Teacher (50 steps, CFG=5) | Student (4 steps, 500 train steps) | Student (4 steps, 2000 train steps) |
|---|---|---|
 |
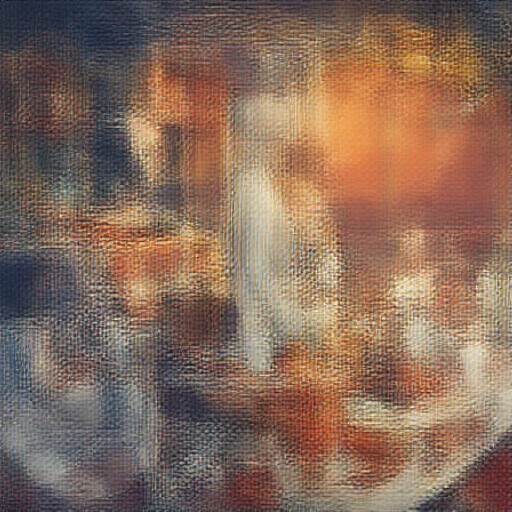 |
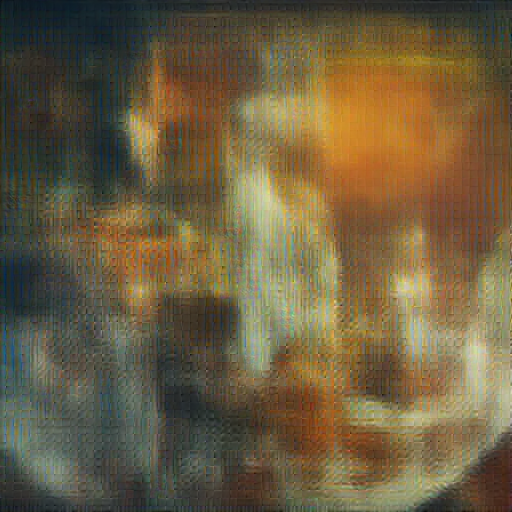 |
Prompt: “The image displays a promotional advertisement for a speaker system. At the top of the image, in bold red letters…“
| Teacher (50 steps, CFG=5) | Student (4 steps, 500 train steps) | Student (4 steps, 2000 train steps) |
|---|---|---|
 |
 |
 |
This last example is the most encouraging — the student at 2000 steps picks up the layout (bold text, speaker image, URL at bottom) even though the details are still muddy. It shows the student is learning structure, just slowly at this tiny scale. This is expected: 500-2000 steps with batch_size=1 on 98 prompts is barely scratching the surface. The LADD paper uses 50K-200K steps with large batch sizes. The production 8-GPU run (20K steps, effective batch 64) should close this gap significantly.
Training progression
We tracked KID against 416 teacher-generated reference images (CFG=5, corrected scheduler) at different training checkpoints:
| Training steps | KID (↓ better) | d_loss | Observation |
|---|---|---|---|
| 500 | 0.0637 ± 0.0053 | 0.0 | Coarse structure emerges |
| 2000 | 0.0702 ± 0.0058 | 0.0 | KID worsens — disc collapse |
The KID worsening from 500 to 2000 steps was our first signal that something was off with the training dynamics. The discriminator loss collapsing to 0 at batch_size=1 meant the hinge loss saturated — the disc could perfectly separate real from fake with just 1 sample, providing no useful gradient.
This is expected at bs=1 and not a sign of discriminator dominance — the hinge margin of ±1 is trivially achieved with a single sample. At the production batch size of 64 (8 GPUs × 4 per-GPU × 2 grad accum), this saturation should resolve.
Overfit experiments
To verify the architecture itself works, we ran two overfit tests on just 10 prompts:
| Experiment | LR | Result |
|---|---|---|
| Aggressive (slr=1e-4, dlr=1e-3) | 20× higher | Diverged — pure noise output |
| Winning LR (slr=5e-6, dlr=5e-5) | Standard | Semantically correct but blue color shift |
The winning-LR overfit produced recognizable images matching prompts — proof that the gradient flow and architecture work. The blue color shift was mode collapse from tiny data: with 10 prompts and bs=1, the student oscillates between pleasing individual prompts instead of learning general features.
Key scaling evidence:
- Text conditioning works — compositions match prompts (98-prompt run)
- More data = better images (98 prompts > 10 prompts)
- More steps = better KID (500 steps: 0.00804 → 2000 steps: 0.00723, pre-fix)
- Gradient flow confirmed — weight deltas grow, grad norms are non-zero
- Discriminator active — d_loss oscillates, not collapsed
The bottleneck is compute and data scale, not architecture.
W&B run links
All experiments are tracked on W&B under project yeun-yeungs/ladd:
- v2 corrected training (500 steps)
- v2 eval at 500 steps
- v2 eval at 2000 steps
- v2 training at 2000 steps
7. Scaling Up: The FSDP Journey

Why FSDP?
On a single A100 80GB, the memory budget is brutal:
| Component | Size |
|---|---|
| Student (bf16) | 12 GB |
| Teacher (bf16) | 12 GB |
| Student optimizer (fp32 Adam) | 24 GB |
| Activations (512px, grad ckpt) | ~30 GB |
| Total | ~78 GB → OOM |
We first tried 8-bit Adam (bitsandbytes) to cut optimizer states from 24 GB to 6 GB. This worked at 256px but still OOM’d at 512px due to activation memory. The real solution was multi-GPU.
DeepSpeed: 9 ways to fail
Before FSDP, we tried DeepSpeed ZeRO-2 with CPU optimizer offload. It failed in 9 distinct ways — each one a lesson in why DeepSpeed assumes single-model training:
- Dual engine crash — wrapping both student and discriminator caused
IndexErrorin gradient reduction - Two-Accelerator pattern — failed with
mpi4pyerrors on seconddeepspeed.initialize() - Student LR stuck at 0 — DeepSpeed’s internal WarmupLR didn’t configure correctly through Accelerate’s “auto” values
- Frozen disc broke gradient flow —
discriminator.requires_grad_(False)during gen step severed the computation graph, student grad norms were zero - Double gradient reduction — both
d_loss.backward()andg_loss.backward()triggered ZeRO-2’s reduction hooks on student params - Grad norms always zero — captured after
zero_grad(); ZeRO-2 manages gradients in internal buffers - Checkpoint write failure —
PytorchStreamWriter failedon the ~24GB optimizer state file os.execv+teeincompatibility — experiment runner output not captured- GPU memory leak via
fork()— parent process held GPU memory, child OOM’d
Conclusion: DeepSpeed ZeRO is designed for single-model training. The GAN setup with alternating D/G updates, cross-model gradient flow, and two optimizers is fundamentally incompatible.
FSDP configuration
FSDP (Fully Sharded Data Parallel) worked cleanly because it operates at the module level rather than the optimizer level. Our config wraps each of the 30 transformer blocks as separate FSDP units:
From training/fsdp_config.yaml:
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_transformer_layer_cls_to_wrap: ZImageTransformerBlock
fsdp_sharding_strategy: FULL_SHARD
fsdp_backward_prefetch: BACKWARD_PRE
fsdp_use_orig_params: true # Required for per-param optimizer groups
fsdp_state_dict_type: FULL_STATE_DICT
Key design choice: the teacher is NOT wrapped in FSDP — it’s replicated on every GPU. At 12 GB in bf16, it fits easily on 80GB A100s, and it only does forward passes (no optimizer states to shard). Wrapping it would add FSDP all-gather overhead for no memory benefit.
Memory per GPU with FSDP
| Component | Per-GPU Size |
|---|---|
| Student (sharded 1/8) | ~1.5 GB |
| Student optimizer (sharded 1/8) | ~6 GB |
| Teacher (full replica) | ~12 GB |
| Discriminator | ~0.03 GB |
| Activations + grad checkpointing | ~4-6 GB |
| Total | ~26 GB / 80 GB |
Comfortable margin. No need for 8-bit Adam, CPU offloading, or precomputed text embeddings on the cluster.
Production launch
From training/train_ladd.sh:
accelerate launch \
--config_file training/fsdp_config.yaml \
training/train_ladd.py \
--train_batch_size=4 \
--gradient_accumulation_steps=2 \
--max_train_steps=20000 \
--learning_rate=5e-6 \
--learning_rate_disc=5e-5 \
--gen_update_interval=3 \
--mixed_precision=bf16 \
--gradient_checkpointing \
--checkpointing_steps=2000 \
--validation_steps=2000
Effective batch size: $4 \times 8 \times 2 = 64$. Target: 20K steps in ~2 hours.
8. The Hard Lessons: Blunders & Principles
This section is the most valuable part of this post. We made mistakes that cost days of debugging and invalidated entire experiment rounds. They cluster into four themes, each with a principle we now follow.
Theme 1: Validate your baseline before tuning anything
We ran 21 hyperparameter experiments and found a configuration that scored KID = 0.000869 — an 89% improvement over baseline. Then we discovered five critical bugs in the training pipeline, and every single KID number became meaningless.
Bug 1: Scheduler linspace off-by-one
Our custom FlowMatchEulerDiscreteScheduler.set_timesteps() had a subtle indexing error:
# BROKEN — leaves 11% residual noise at the final step
timesteps = np.linspace(sigma_max_t, sigma_min_t, num_inference_steps + 1)[:-1]
# CORRECT — matches diffusers exactly
timesteps = np.linspace(sigma_max_t, sigma_min_t, num_inference_steps)
With 50 inference steps, the scheduler’s smallest sigma was 0.109 instead of reaching 0.0. Teacher images had 11% residual noise — they looked blurry, and we were evaluating KID against blurry references.
Bug 2: Teacher images generated without CFG
The precompute_fid_reference.py script generated teacher reference images with guidance_scale=0. The Z-Image model requires CFG (~5.0) for sharp, well-composed images. Without it, outputs were unconditional-like and lacked detail. On top of that, TeaCache was enabled (teacache_thresh=0.5), skipping 75% of transformer computations for speed at the cost of further quality degradation.
The difference is stark — here’s the same prompt rendered with CFG=0 vs CFG=5 (from our W&B debug-teacher-cfg-sweep run):
Prompt: “Two wine bottles with green glass and white labels…“
| CFG=0 (no guidance) | CFG=3 | CFG=5 (selected) |
|---|---|---|
 |
 |
 |
Without CFG, the labels are illegible smudges. With CFG=5, the text is crisp and the bottle shapes are well-defined. We were evaluating our student against the left image — no wonder the KID numbers looked deceptively good.
Bug 3: Student input was pure noise regardless of timestep
The student at timestep $t = 0.25$ should see a mostly-clean input: $x_t = 0.75 \cdot x_0 + 0.25 \cdot \varepsilon$. Instead, it received pure noise at every timestep. At $t = 0.25$, the student was told “you’re almost done denoising” while looking at pure static — it had no signal about what to reconstruct.
Bug 4: No velocity-to-latent conversion
The student predicts velocity $v_\theta$, but the code used raw velocity as the denoised prediction. The correct conversion is $\hat{x}0 = x_t - t \cdot v\theta$ — without it, the discriminator received meaningless inputs.
Bug 5: “Real” samples were noise vs. noise
The LADD paper (Section 3.2) specifies that “real” samples should be teacher-generated images re-noised to the discriminator’s timestep. Our code used add_noise(noise1, noise2, t_hat) — random noise mixed with random noise. The discriminator was learning to distinguish two flavors of Gaussian noise, which is a trivially learnable but useless task.
The corrected training flow:
OFFLINE:
teacher_x0 = teacher.generate(prompt, cfg=5, steps=50, output_type="latent")
ONLINE per step:
1. x_t = (1-t) * teacher_x0 + t * ε ← student input (Bug 3 fix)
2. v = student(x_t, t, prompt) ← velocity prediction
3. x̂_0 = x_t - t * v ← denoised latent (Bug 4 fix)
4. fake_noisy = (1-t̂) * x̂_0 + t̂ * ε₁ ← re-noise for disc
5. real_noisy = (1-t̂) * teacher_x0 + t̂ * ε₂ ← real path (Bug 5 fix)
The worst part: the relative ordering of hyperparameter configs from Round 1 likely still holds (all experiments used the same broken pipeline), but the optimal GI flipped from 8 to 3 once the discriminator faced a genuinely hard discrimination task. We had to re-run the entire sweep.
Principle: Never tune hyperparameters on an unvalidated baseline. Before any sweep, verify: (1) the teacher produces sharp images independently, (2) the training loop’s math matches the paper step-by-step, (3) a single training step produces finite, non-trivial gradients. Log teacher outputs to W&B as a sanity check before starting experiments.
Theme 2: Budget compute realistically — and plan for sacrifices
We had 500K curated prompts but needed teacher latents (50-step generation with CFG=5) for every one. We benchmarked:
| Batch size | Time per image | Peak VRAM |
|---|---|---|
| 1 | 8.9s | 21.9 GB |
| 4 | 7.5s | 25.2 GB |
| 8 | 7.3s | 29.5 GB |
At 7.3s/image with embarrassingly parallel sharding (each GPU processes an independent subset of prompts, no communication needed), precomputing all 500K latents across 8 A100s would take:
\[\frac{500{,}000 \times 7.3}{8} = 456{,}250 \text{ seconds} \approx 127 \text{ hours}\]We had 6 hours of compute. The math was brutal: we could precompute roughly 10K latents in 4 hours — 2% of our dataset. Training would repeat each latent ~128 times over 20K steps.
This was a hard trade-off we should have modeled before curating 500K prompts. The curation pipeline (Part 1) was optimized for diversity and prompt quality, which is still valuable for future runs. But for the first training run, 10K stratified-sampled prompts with heavy repetition was the reality.
Principle: Model the full compute pipeline end-to-end before committing. Teacher latent precomputation is not a minor preprocessing step — for a 6B model at 50 steps with CFG, it dominates the compute budget. Calculate wall-clock time for every stage, including precomputation, and work backward from your time budget to determine feasible dataset size.
Theme 3: Distributed training requires whole-system thinking
FSDP debugging consumed significant time because distributed primitives interact in non-obvious ways with GAN training patterns.
The get_state_dict hang
FSDP’s accelerator.get_state_dict() is a collective operation — all ranks must call it, not just rank 0. Our validation code called it inside an if accelerator.is_main_process: guard. Rank 0 entered the gather; ranks 1-7 skipped it. Deadlock.
From the fix in train_ladd.py:263:
# get_state_dict is a collective op under FSDP — ALL ranks must call it.
state_dict = accelerator.get_state_dict(student_model)
# Only rank 0 does file I/O
if not accelerator.is_main_process:
return
Checkpoint format issues
accelerator.save_state() is incompatible with 8-bit Adam under FSDP. PyTorch’s .pt format had temp file issues with large state dicts. The fix: save student weights as safetensors, gate save_state behind if not is_fsdp.
Validation subprocess can’t log to parent’s W&B
Our async validation spawns a subprocess on a separate GPU. The child process can’t resume the parent’s W&B run context. Fix: the parent process logs the eval table after the subprocess completes.
The costly get_state_dict double-call
get_state_dict() takes ~10 minutes for FSDP gather on a 6B model. We were calling it separately for checkpointing and validation — 20 minutes wasted when they coincide at the same step. Fix: one call, shared between both.
if need_checkpoint or need_validation:
state_dict = accelerator.get_state_dict(student) # Single gather
if need_checkpoint:
save_checkpoint(state_dict)
if need_validation:
launch_validation(state_dict)
Principle: Distributed ops are collective — think in terms of what all ranks do, not just rank 0. Before adding any distributed code: (1) identify which operations are collective (all-gather, all-reduce, broadcast), (2) ensure every rank hits every collective in the same order, (3) run a 2-GPU smoke test before scaling to 8. We built
scripts/smoke_test_fsdp.shto catch these issues early.
Theme 4: Instrument first, debug later
Several of our bugs were only caught because we logged the right things to W&B — and several persisted because we didn’t log the right things early enough.
What caught the scheduler bug: We logged teacher images to W&B as part of a CFG sweep (debug-teacher-cfg-sweep). The images looked blurry at all CFG values. This prompted investigation of the scheduler, which revealed the linspace off-by-one. Without visual inspection, we would have continued tuning hyperparameters against a broken baseline.
What we should have logged earlier:
- Teacher-generated images at step 0 (before any training)
- The exact timestep and sigma values the scheduler produces
- A side-by-side of student input $x_t$ at different timesteps (would have caught Bug 3 immediately — “why does t=0.25 look like pure noise?”)
- Decoded student predictions $\hat{x}_0$ (would have caught Bug 4 — raw velocity doesn’t look like an image)
The pixelated artifact investigation: Student outputs showed pixelated grid artifacts. The investigation led us to the scheduler parameters, which led to the linspace bug. The fix required regenerating all teacher reference images and latents, then re-running every experiment.
Principle: Log intermediate representations, not just scalar metrics. Scalars like KID and d_loss tell you that something is wrong; images and tensors tell you what. At minimum, log: teacher outputs at step 0, student predictions every N steps, input $x_t$ at different timesteps, and scheduler sigma schedules. A 5-minute W&B setup saves days of blind debugging.
9. Summary & Next Steps
We built a LADD training framework that distills a 6.15B image model from 50 steps to 4. The key components:
- Architecture: Student (6.15B, trainable) + Teacher (6.15B, frozen) + Discriminator (14M, 6 multi-scale conv heads on teacher features)
- Loss: Adversarial hinge loss only — no distillation loss, no pixel-space comparison
- Training: Asymmetric D/G updates (3:1), logit-normal re-noising ($m=0.5$, $s=1.0$), timestep curriculum
- Infrastructure: FSDP across 8× A100 80GB, ~26 GB per GPU, 20K steps in ~2 hours
Single-GPU experiments confirmed the architecture works: the student produces semantically correct images that match prompts, quality improves with more data and steps, and gradient flow is healthy. The remaining gap is scale — batch size 64 (vs 1), 10K+ prompts (vs 98), and 20K steps (vs 2000).
What’s next
- Run the production 8-GPU training (20K steps, effective batch 64, 10K precomputed latents)
- Compare 4-step student outputs against 50-step teacher at scale
- If time permits: precompute more latents (50K+) for a second run with less repetition
- Evaluate on held-out test set (13K prompts) with KID and visual quality assessment
The code is open source at github.com/vionwinnie/Z-Image-LADD-distillation.
10. Key References
| Year | Paper | Contribution |
|---|---|---|
| 2023 | Lipman et al., Flow Matching for Generative Modeling | Flow matching framework — linear interpolation between noise and data, velocity prediction |
| 2023 | Sauer et al., Adversarial Diffusion Distillation (ADD) | First adversarial distillation for diffusion — SDXL-Turbo, 1-4 step generation |
| 2024 | Sauer et al., LADD: Latent Adversarial Diffusion Distillation | Moves discrimination to teacher’s latent features — scalable, no pixel losses, 14M discriminator for 6B+ models |
| 2018 | Miyato et al., Spectral Normalization for GANs | Hinge loss and spectral norm — stabilizes adversarial training |
| 2018 | Perez et al., FiLM: Visual Reasoning with Feature-wise Linear Modulation | FiLM conditioning — scale/shift modulation used in discriminator heads |